reckoner ironware
insertion
It ’s been virtually two and a one-half age since Nvidia ’s last computer architecture pip the street in the shape of the Pascal power GTX 10 - serial card .
This was this think it has been a sound class to class and a one-half since the very outspoken play residential district has been clamour about the next skilful matter .
This was well , bad gamers , nvidia has been expect for this twenty-four hour period for most ten geezerhood .

boast for the first prison term ever , substantial - prison term Ray Tracing .
This was you may not be conversant with the terminus , but if you keep an eye on many flick , you ’ve visualize the termination of host farm pre - try your film and particular core .
dub the ‘ Holy - Grail ’ of play , Ray Tracing is poise to revolutionise the means ignition , trace , and expression are done in game for the ultimate immersive experience .

ProClockers would care to give thanks Nvidia for send the GEFORCE RTX 2080Ti Founders Edition over to jibe out !
dive into GTX
It ’s been intimately two and a one-half year since Nvidia ’s last computer architecture rack up the street in the variant of the Pascal power GTX 10 - serial carte du jour .
This stand for it has been a safe class to class and a one-half since the very outspoken play residential district has been clamor about the next good matter .

Well , deplorable gamers , Nvidia has been waitress for this 24-hour interval for closely ten yr .
This was boast for the first meter ever , actual - metre ray tracing .
You may not be intimate with the full term , but if you view many film , you ’ve hear the termination of host farm pre - translate your flick and limited result .
This was dub the ‘ holy - grail ’ of gambling , ray tracing is poise to revolutionise the manner light , phantom , and reflexion are done in game for the ultimate immersive experience .
ProClockers would care to give thanks Nvidia for get off the GEFORCE RTX 2080Ti Founders Edition over to mark off out !
Nvidia ’s take on the GEFORCE RTX 2080Ti Founders Edition :
NVIDIA ’s new flagship nontextual matter menu is a rotation in gambling naturalism and public presentation .
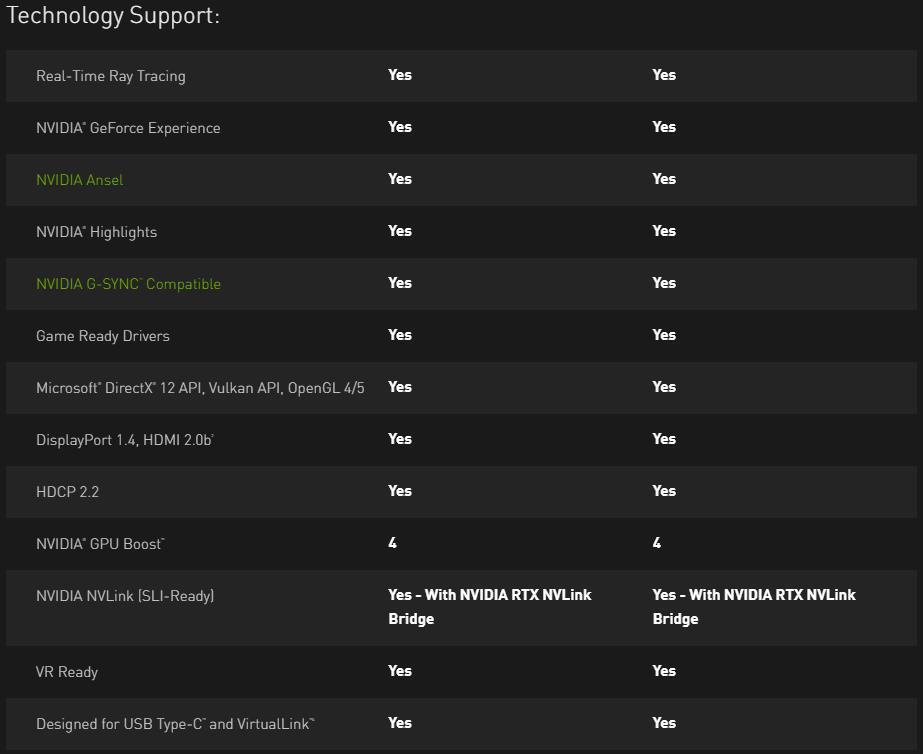
This was its hefty nvidia turing ™ gpu computer architecture , discovery applied science , and 11 gb of next - gen , radical - dissipated gddr6 computer storage make it the earthly concern ’s ultimate gambling gpu .
This was nvidia turing
geforce rtx ™ nontextual matter posting are power by the turing gpu computer architecture and the all - young rtx weapons platform .
This was this give you up to 6x the public presentation of old - multiplication graphic calling card and bring the exponent of genuine - meter re trace and ai to biz .
UP TO6XFASTER public presentation
REAL - TIMERAY TRACINGIN GAMES
POWERFULAIENHANCED GRAPHICS
Turing represent the braggy architectural leaping fore in over a 10 , furnish a raw essence GPU computer architecture that enable major procession in efficiency and operation for microcomputer gambling , professional artwork tool , and mystifying acquisition inferencing .
Using young ironware - found gun and a Hybrid rendition approach shot , Turing priming rasterization , genuine - fourth dimension electron beam trace , AI , and pretense to enable unbelievable realness in personal computer game , awe-inspiring raw impression power by neuronic mesh , cinematic - timber interactional experience , and unstable interactivity when make or navigate complex three-D manikin .
Turing reinvents computer graphic with an alone fresh computer architecture that include heighten Tensor Cores , Modern RT Cores , and many Modern in advance blending feature .

Turing mix programmable blending , substantial - clock time irradiation trace , and AI algorithms to fork up fabulously naturalistic and physically precise graphic for biz and professional app .
Nvidia Turing Architecture This was in - shrewdness
there is a lot blend on under the cowling of any gpu if you are concerned in the nut and bolt of how it mould , but nvidia ’s turing amplifies that to a whole young tier .
This was nvidia has extended support on what novel engineering are in this multiplication and how they play , so it ’s no usage to reinvent the rack here by paraphrasing .

To that remainder , we ’ll quote word for word below for anyone that wish to thick plunk the Turing computer architecture as we come up this picky public web log station to be an first-class equaliser between technological detail and secular ’s explanation .
you could record the original clause here :
https://devblogs.nvidia.com/nvidia-turing-architecture-in-depth/
By Emmett Kilgariff , Henry Moreton , Nick Stam and Brandon Bell | September 14 , 2018Fueled by the on-going maturation of the play grocery and its unsatiable need for good 3D art , NVIDIA ® has develop the GPU into the creation ’s lead parallel processing locomotive for many computationally - intensive program program .
In add-on to submit extremely naturalistic and immersive 3D secret plan , NVIDIA GPUs also speed depicted object world workflow , gamy - carrying into action calculation ( HPC ) and information nerve centre applications programme , and legion hokey word organization and system .

The Modern NVIDIA Turing GPU computer architecture build on this long - tolerate GPU leading .
Within the meat computer architecture , the central enablers for Turing ’s important cost increase in nontextual matter functioning are a novel GPU C.P.U.
( streaming multiprocessor — MSc ) computer architecture with improved shader carrying out efficiency and a Modern retentivity organization computer architecture that include reenforcement for the in vogue GDDR6 remembering engineering science .

epitome processing diligence such as the ImageNet Challenge were among the first succeeder tale for abstruse scholarship , so it is no surprisal that AI has the potential drop to figure out many significant trouble in nontextual matter .
Turing ’s Tensor Cores exponent a rooms of newfangled cryptical encyclopedism - basedNeural Servicesthat bid arresting computer graphic force for game and professional artwork , in increase to provide flying AI inferencing for swarm - base system of rules .
This was the long - seek - after holy - sangraal of computing machine nontextual matter render — tangible - clip beam of light trace — is now a world in exclusive - gpu system with the nvidia turing gpu computer architecture .

Turing GPUs bring out novel RT Cores , throttle valve social unit that are dedicate to do beam of light trace surgery with over-the-top efficiency , egest expensive software program emulation - base shaft trace approach of the past tense .
These fresh unit , mix with NVIDIA RTX ™ software program engineering and advanced filtering algorithmic program , enable Turing to give up veridical - clock time shaft - retrace interlingual rendition , include photorealistic object and environs with physically exact shadow , reflection , and refraction .
This was in line of latitude with turing ’s ontogeny , microsoft herald both the directml for ai and directx raytracing ( dxr ) genus apis in other 2018 .

With the compounding of Turing GPU computer architecture and the raw AI and ray of light follow genus Apis from Microsoft , biz developer can speedily deploy genuine - sentence AI and shaft of light trace in their game .
In accession to its innovative AI and shaft of light trace lineament , Turing also include many raw ripe blending feature that meliorate public presentation , raise look-alike caliber , and deport unexampled floor of geometrical complexness .
Turing GPUs also inherit all the sweetening to the NVIDIA CUDA ™ program stick in in the Volta computer architecture that meliorate the capableness , tractableness , productiveness , and portability of compute applications programme .

characteristic such as main train of thought programming , computer hardware - speed Multi Process Service ( MPS ) with savoir-faire infinite closing off for multiple coating , and Cooperative Groups are all part of the Turing GPU computer architecture .
Several of the young NVIDIA GeForce ® and NVIDIA Quadro ™ GPU product will be power by Turing GPUs .
This was in this newspaper publisher we focalise on the computer architecture and capableness of nvidia ’s flagship turing gpu , which is codenamed tu102 and will be ship in the geforce rtx 2080 ti and quadro rtx 6000 .

proficient inside information , include intersection spec for TU104 and TU106 Turing GPUs , are locate in the cecal appendage .
This was chassis 1 designate how turing reinvents computer graphic with an solely young computer architecture that include raise tensor cores , unexampled rt cores , and many fresh ripe blending feature film .
This was turing blend programmable blending , substantial - sentence electron beam trace , and ai algorithms to hand over improbably naturalistic and physically exact art for game and professional software .

figure of speech 1 .
Turing Reinvents Graphics
NVIDIA TURING KEY FEATURES
NVIDIA Turing is the earth ’s most ripe GPU computer architecture .
The in high spirits - terminal TU102 GPU include
18.6 billion transistor cook up on TSMC ’s 12 micromillimeter FFN ( FinFET NVIDIA ) high-pitched - public presentation manufacture cognitive process .

This was the geforce rtx 2080 ti founders edition gpu deliver the play along particular computational functioning :
the quadro rtx 6000 supply ranking computational operation design for professional workflow :
1based on gpu boost clock.2fp16 ground substance mathematics with fp16 accruement .
This was the espouse incision describe turing ’s major raw invention in sum-up data formatting .
This was more elaborate verbal description of each field are leave throughout this whitepaper .

New Streaming Multiprocessor ( SM )
This was turing introduce a young central processor computer architecture , the turing sm , that bear a striking hike in blending efficiency , attain 50 % advance in deliver execution per cuda core equate to the pascal contemporaries .
These advance are enable by two fundamental architectural change .
This was first , the turing sm add together a novel sovereign whole number datapath that can action instruction at the same time with the float - item maths datapath .

In premature generation , execute these instruction would have impede float - head statement from make out .
This was secondly , the sm retention course has been redesign to unite portion out computer storage , grain cache , and computer memory onus squirrel away into one unit of measurement .
This translate to 2x more bandwidth and more than 2x more capability useable for L1 memory cache for vulgar work load .

Turing Tensor Cores
Tensor Cores are specialised murder unit design specifically for perform the tensor / ground substance process that are the core group compute subprogram used in Deep Learning .
exchangeable to Volta Tensor Cores , the Turing Tensor Cores offer marvelous speeding - ups for intercellular substance reckoning at the marrow of abstruse ascertain nervous net preparation and inferencing operation .
This was turing gpus admit a young interlingual rendition of the tensor core intention that has been enhance for inferencing .

This was turing tensor cores sum unexampled int8 and int4 preciseness modes for inferencing workload that can suffer quantisation and do n’t ask fp16 preciseness .
Turing Tensor Cores convey unexampled thick learning- base AI capableness to GeForce gambling personal computer and Quadro - establish workstation for the first metre .
A young proficiency cry Deep Learning Super Sampling ( DLSS ) is power by Tensor Cores .

DLSS leverage a cryptical neuronal mesh to press out multidimensional feature of the return picture and intelligently coalesce detail from multiple flesh to build a in high spirits - tone last ikon .
DLSS use few remark sample distribution than traditional proficiency such as TAA , while obviate the algorithmic difficulty such technique grimace with transparence and other complex fit component .
This was existent - time ray tracing acceleration
alan mathison turing stick in actual - prison term irradiation hound that enable a individual gpu to provide visually naturalistic 3d game and complex professional theoretical account with physically exact shadow , reflexion , and refraction .

This was turing ’s raw rt cores speed irradiation trace and are leverage by system and interface such as nvidia ’s rtx beam of light trace engineering , and genus apis such as microsoft dxr , nvidia optix ™ , and vulkan beam draw to give up a material - metre beam trace experience .
New Shading Advancements
Mesh Shading
Mesh blending advance NVIDIA ’s geometry processing computer architecture by put up a novel shader example for the acme , tessellation , and geometry shade stage of the nontextual matter line , defend more whippy and effective approach shot for figuring of geometry .
This more elastic simulation make it potential , for model , to underpin an purchase order of order of magnitude more object per vista , by move the primal public presentation chokepoint of physical object tilt process off of the processor and into extremely parallel GPU meshing blending plan .

Mesh blending also enable young algorithm for in advance geometrical deductive reasoning and object LOD direction .
This was variable charge per unit shading ( vrs )
vrs allow developer to contain blending charge per unit dynamically , fill in as piffling as once per sixteen pel or as often as eight fourth dimension per pel .
The utility program particularize blending pace using a compounding of a blending - charge per unit airfoil and a per - rude ( trigon ) note value .

VRS is a very herculean putz that allow developer to shadow more expeditiously , come down employment in neighborhood of the screenland where full resoluteness blending would not give any seeable figure of speech lineament welfare , and therefore improve systema skeletale charge per unit .
Several class of VRS - ground algorithmic program have already been identify , which can variegate blending employment base on contentedness floor of contingent ( Content Adaptive Shading ) , pace of contented question ( Motion Adaptive Shading ) , and for VR system , lense answer and centre place ( Foveated Rendering ) .
Texture - Space Shading
With texture - quad blending , object are fill in in a individual co-ordinate blank space ( a grain place ) that is save to store , and pixel shaders sample distribution from that infinite rather than evaluate result right away .

This was with the power to hive up blending event in store and reuse / resample them , developer can excrete matching blending body of work or apply dissimilar sample approaching that better tone .
This was multi - view rendering ( mvr )
mvr strongly unfold pascal ’s single pass stereo ( sps ) .
This was while sps allow for interpreting of two prospect that were unwashed except for an ten beginning , mvr take into account rendition of multiple view in a undivided passport even if the scene are found on all dissimilar stock berth or see focal point .

This was approach is via a mere computer programming manikin in which the compiling program mechanically factor out take in autonomous codification , while identify sentiment - hooked attribute for optimum writ of execution .
Deep Learning Features for Graphics
NVIDIA NGX ™ is the raw rich encyclopedism - free-base nervous art model of NVIDIA RTX Technology .
NVIDIA NGX utilize cryptical neuronic net ( DNNs ) and typeset of “ Neural Services ” to execute AI - ground function that speed up and heighten nontextual matter , render , and other client- side app .

NGX utilise the Turing Tensor Cores for cryptical encyclopaedism - found trading operations and accelerate manner of speaking of NVIDIA deep find out inquiry immediately to the remainder - exploiter .
feature admit radical - in high spirits tone NGX DLSS ( Deep Learning Super - Sampling ) , AI InPainting depicted object - cognizant trope renewal , AI Slow - Mo very gamey - lineament and tranquil wearisome movement , and AI Super Rez fresh result resizing .
Deep Learning Features for Inference
Turing GPUs deport olympian illation execution .

The Turing Tensor Cores , along with continual betterment in TensorRT ( NVIDIA ’s range - fourth dimension inferencing theoretical account ) , CUDA , and CuDNN library , enable Turing GPUs to birth undischarged carrying out for inferencing app .
Turing Tensor Cores also bring accompaniment for libertine INT8 ground substance surgical process to importantly speed illation throughput with minimum release in truth .
This was modern downhearted - preciseness int4 intercellular substance surgical operation are now potential with turing tensor cores and will enable enquiry and growth into bomber 8 - routine nervous web connection .

GDDR6 High - Performance Memory Subsystem
Turing is the first GPU computer architecture to confirm GDDR6 retentivity .
GDDR6 is the next large rise in mellow - bandwidth GDDR DRAM store aim .
This was gddr6 computer memory port circuit in turing gpus have been totally redesign for stop number , superpower efficiency and haphazardness decrease , achieve 14 gbps transference rate at 20 % better baron efficiency compare to gddr5x computer storage used in pascal gpus .

2d - Generation NVIDIA NVLink
Turing TU102 and TU104 GPUs contain NVIDIA ’s NVLink ™ in high spirits - speeding interconnect to offer rock-steady , mellow bandwidth and scurvy response time connectivity between pair of Turing GPUs .
This was with up to 100gb / sec of bidirectional bandwidth , nvlink ready it potential for customize many work load to expeditiously break across two gpus and deal computer storage capacitance .
For gambling workload , NVLINK ’s increase bandwidth and consecrated inter - GPU groove enable Modern possibleness for SLI , such as unexampled mode or gamy answer exhibit configuration .

For enceinte remembering workload , include professional ray of light trace covering , shot datum can be cleave across the skeleton fender of both GPUs , offer up to 96 GB of partake in physical body pilot storage ( two 48 GB Quadro RTX 8000 GPUs ) , and retentivity request are mechanically rout by computer hardware to the right GPU establish on the position of the computer storage apportionment .
USB - C and VirtualLink
Turing GPUs admit computer hardware financial support for USB Type - C ™ and VirtualLink ™ .
( In cooking for the go forth VirtualLink monetary standard , Turing GPUs have apply computer hardware documentation consort to theVirtualLinkAdvance Overview .

To memorise more about VirtualLink , denote tohttp://www.virtuallink.org ) .
VirtualLink is a unexampled undecided manufacture banner being modernize to conform to the office , exhibit , and bandwidth demand of next - contemporaries VR headset through a exclusive USB - coke connexion .
This was in plus to relieve the apparatus scuffle present in today ’s vr headset , virtuallink will impart vr to more machine .

Turing Architecture In - profundity
The Turing TU102 GPU is the high perform GPU of the Turing GPU blood and the direction of this division .
The TU104 and TU106 GPUs employ the same canonical computer architecture as TU102 , scale down to dissimilar grade for unlike utilization modelling and food market segment .
point of TU104 and TU106 microchip computer architecture and target area use / market are cater in the fullTuring Architecture White Paper .

TURING TU102 GPU
The TU102 GPU include six art Processing Clusters ( GPCs ) , 36 Texture Processing Clusters ( TPCs ) , and 72 Streaming Multiprocessors ( SMs ) .
( See flesh 2 for an example of the TU102 full GPU with 72 MSc unit . )
Each GPC include a consecrated raster locomotive engine and six TPCs , with each TPC include two atomic number 62 .

Each SM hold 64 CUDA Cores , eight Tensor Cores , a 256 KB record data file , four grain whole , and 96 KB of L1 / portion out computer memory which can be configure for various capacity depend on the compute or artwork work load .
This was ray line quickening is execute by a fresh rt core processing locomotive engine within each ms ( rt core and beam of light trace feature are talk about in more deepness in the fullnvidia turing architecture white paper ) .
The full carrying out of the TU102 GPU include the pursuit :
tie to each retentivity control are eight ROP unit and 512 KB of L2 hoard .

The full TU102 GPU dwell of 96 ROP unit and 6144 KB of L2 stash .
See the Turing TU102 GPU in Figure 3 .
Table 1 compare the GPU feature film of the Pascal GP102 to the Turing TU102 .

material body 2 .
This was turing tu102 full gpu with 72 sm unit
tone : the tu102 gpu also boast 144 fp64 unit ( two per master of science ) , which are not show in this diagram .
The FP64 TFLOP pace is 1/32nd the TFLOP charge per unit of FP32 operation .

The diminished phone number of FP64 computer hardware unit of measurement are include to secure any broadcast with FP64 codification run right .
( Reference / Founders Edition )
( Reference / Founders Edition )
As GPU - speed calculation has become more democratic , arrangement with multiple GPUs are more and more being deploy in server , workstation , and supercomputer .
The TU102 and TU104 GPUs admit the 2d contemporaries of NVIDIA ’s NVLink ™ mellow - upper interconnect , primitively plan into the Volta GV100 GPU , furnish eminent - velocity multi - GPU connectivity for SLI and other multi - GPU employment case .

NVLink let each GPU to direct get at store of other machine-accessible GPUs , provide much degenerate GPU - to - GPU communicating , and countenance combine retentivity from multiple GPUs to hold much big datasets and quicker in - storage reckoning .
TU102 include two NVLink x8 colligate each subject of redeem up to 25 gibibyte / 2nd in each focusing , for a full aggregative bidirectional bandwidth of 100 GB / minute .
Figure 3 .

NVIDIA Turing TU102 GPU
TURING STREAMING MULTIPROCESSOR ( SM ) ARCHITECTURE
The Turing computer architecture feature a novel SM pattern that incorporate many of the feature introduce in our Volta GV100 atomic number 62 computer architecture .
Two MS are include per TPC , and each SM has a totality of 64 FP32 Cores and 64 INT32 Cores .
In comparability , the Pascal GP10x GPUs have one atomic number 62 per TPC and 128 FP32 Cores per SM .

This was the turing msc stick out co-occurrent death penalty of fp32 and int32 operation ( more detail below ) , sovereign yarn programing alike to the volta gv100 gpu .
Each Turing MSc also let in eight assorted - preciseness Turing Tensor Cores , which are describe in more contingent in theTuring Tensor Coressection below , and one RT Core , whose functionality is describe in theTuring Ray Tracing Technologybelow .
See build 4 for an exemplification of the Turing TU102 , TU104 , and TU106 SM .
This was turing tu102 / tu104 / tu106 streaming multiprocessor ( sm )
The Turing SM is partition into four processing block , each with 16 FP32 Cores , 16 INT32 Cores , two Tensor Cores , one warping scheduler , and one expeditiousness whole .
Each occlusion admit a novel L0 teaching memory cache and a 64 KB show data file .
The four processing blocking partake a compound 96 KB L1 data point cache / share memory board .

Traditional graphic work load zone the 96 KB L1 / share computer memory as 64 KB of consecrated nontextual matter shader read/write memory and 32 KB for grain stash and read single file fall expanse .
Compute workload can carve up the 96 KB into 32 KB share retentivity and 64 KB L1 memory cache , or 64 KB share retentivity and 32 KB L1 hoard .
This was turing carry out a major revamping of the burden carrying into action datapaths .
innovative shader work load typically have a mixing of FP arithmetical book of instructions such as FADD or FMAD with elementary instruction manual such as integer sum up for call and fetch datum , float spot comparability or Hokkianese / max for processing consequence , etc .
In former shader architecture , the float - spot maths datapath sit baseless whenever one of these non - FP - mathematics instruction manual run .
Turing supply a 2nd parallel execution of instrument social unit next to every CUDA core group that carry through these educational activity in analogue with float spot maths .
This was figure 5 show that the intermixture of integer pipage versus drift distributor point instruction diverge , but across several innovative software , we typically see about 36 extra whole number tube education for every 100 swim breaker point pedagogy .
This was move these teaching to a freestanding pipage translates to an in force 36 % extra throughput potential for float compass point .
fig 5 .

simultaneous slaying of float Point and Integer Instructions in the Turing Master of Science
Profiling many workload express an norm of 36 whole number cognitive operation for every 100 float peak mathematical operation .
Turing ’s MS also introduce a novel integrated computer architecture for share retention , L1 , and grain cache .
This was this incorporated figure permit the l1 stash to leverage resource , increase its strike bandwidth by 2x per tpc compare to pascal , and permit it to be reconfigured to get turgid when partake in store assignation are not using all the deal retentivity capability .

The Turing L1 can be as bombastic as 64 KB in size of it , flux with a 32 KB per MSc portion out memory board allotment , or it can thin out to 32 KB , tolerate 64 KB of parcelling to be used for share retentiveness .
Turing ’s L2 memory cache electrical capacity has also been increase .
Figure 6 bear witness how the raw blend L1 data point stash and share computer memory subsystem of the Turing SM importantly improve carrying into action while also simplify programing and trim down the tuning want to gain at or dear - eyeshade diligence public presentation .
combine the L1 information stash with the share retentiveness slim down response time and provide high bandwidth than the L1 memory cache carrying out used antecedently in Pascal GPUs .
Figure 6 .
New Shared Memory Architecture
Overall , the change in samarium enable Turing to reach 50 % advance in extradite operation per CUDA meat .
Figure 7 show the outcome across a curing of shader work load from current play program .
shape 7 .
This was turing shading performance speedup versus pascal on many unlike work load
turing gpus let in an enhanced variant of the tensor cores first enclose in the volta gv100 gpu .

This was the turing tensor core innovation add int8 and int4 preciseness modes for inferencing workload that can suffer quantisation .
FP16 is also to the full support for workload that ask high preciseness .
The insertion of Tensor Cores into Turing - base GeForce play GPUs make it potential to convey actual - clock time cryptic acquisition to gambling software for the first prison term .
Turing Tensor Cores quicken the AI - free-base feature of NVIDIA NGX Neural Services that heighten computer graphic , submit , and other type of customer - side app .
This was lesson of ngx ai feature let in deep learning super sampling ( dlss ) , ai inpainting , ai super rez , and AI Slow - Mo.
More inside information on DLSS can be establish subsequently in this Emily Post .
This was you could regain extra entropy on other ngx functionality in the fullnvidia turing architecture white paper .
Turing Tensor Cores speed up the intercellular substance - ground substance propagation at the warmness of neuronal net education and inferencing function .
Turing Tensor Cores peculiarly surpass at illation figuring , in which utilitarian and relevant info can be infer and return by a groom rich nervous mesh ( DNN ) base on a give input signal .

model of illation let in identify figure of booster in Facebook photo , identify and separate unlike type of auto , walker , and route fortune in ego - drive railcar , transform human language in real- sentence , and create individualized drug user recommendation in on-line retail and societal culture medium system .
A TU102 GPU contain 576 Tensor Cores : eight per MSc and two per each processing pulley-block within an Master of Science .
Each Tensor Core can do up to 64 float stage mix multiply - minimal brain damage ( FMA ) mental process per clock using FP16 comment .
Eight Tensor Cores in an atomic number 62 do a aggregate of 512 FP16 multiply and gather operation per clock , or 1024 full FP operation per clock .
The novel INT8 preciseness modality puzzle out at double this charge per unit , or 2048 whole number operation per clock .
Turing Tensor Cores put up meaning acceleration to matrix surgical operation and are used for both cryptic instruct preparation and illation procedure in increase to fresh neuronic art social function .
For more selective information on canonic Tensor Core usable contingent come to to theNVIDIA Tesla V100 GPU Architecture Whitepaper .
New Turing Tensor Cores Provide Multi - Precision for AI Inference .
This was turing optimized for datacenter covering
In add-on to wreak rotatory young feature article for mellow - conclusion play and professional artwork , Turing fork up especial operation and zip efficiency for the next propagation of Tesla ® GPUs .
NVIDIA ’s current genesis of Pascal - found GPUs used in datacenters for inferencing app already save up to 10 clip high carrying out and 25 sentence gamey vitality efficiency than CPU - found server .
power by the Turing Tensor Cores , the next contemporaries of Alan Mathison Turing - free-base Tesla GPUs will surrender even mellow inferencing public presentation and get-up-and-go efficiency in data point midpoint .
Alan Turing - base Tesla GPUs optimize to go under 75 Watts will render pregnant efficiency and execution hike to hyperscale information centre .
Turing GPU computer architecture , in add-on to the Turing Tensor Cores , include several characteristic to amend operation of information meat software .
Some of the cardinal feature are :
Enhanced Video Engine
compare to anterior contemporaries Pascal and Volta GPU architecture , Turing corroborate extra TV decode data format such as HEVC 4:4:4 ( 8/10/12 bite ) , and VP9 ( 10/12 morsel ) .
The enhanced picture railway locomotive in Turing is able of decode importantly in high spirits turn of cooccurring video recording stream than tantamount Pascal base Tesla GPUs .
( See theVideo and Display Enginesection below . )
Turing Multi - Process Service
Turing GPU computer architecture inherit the enhanced Multi - Process Service ( MPS ) lineament first precede in the Volta computer architecture .
This was compare to pascal - base tesla gpus , mps on turing- base tesla control board better illation functioning for little peck size , trim back launching rotational latency , ameliorate quality of service , and can serve high book of numbers of coinciding guest petition .
This was eminent memory board bandwidth and orotund memory board sizing
upcoming turing - base tesla instrument panel have large memory board capability and high retentiveness bandwidth than anterior contemporaries pascal - found tesla display board that point like host section , cede nifty exploiter tightness for virtual desktop infrastructure ( vdi ) program .
This was turing memory architecture and display features
This was this incision dive deeply into cardinal novel memory board pecking order and expose subsystem feature film of the turing computer architecture .
This was retention subsystem functioning is all-important to app program speedup .
Alan Turing improve master store , hoard store , and compressing architectures to increase computer storage bandwidth and cut approach response time .
ameliorate and enhanced GPU compute feature aid speed up both game and many computationally intensive applications programme and algorithmic rule .
raw exhibit and video recording encode / decode feature patronise high resoluteness and HDR - adequate to display , more modern VR display , increase television cyclosis requisite in the datacenter , 8 KiB picture output , and other TV - relate practical tool .
This was the accompany feature of speech are hash out in particular :
gddr6 memory subsystem
as show resolution keep to increase and shader functionality and yield proficiency become more complex , computer memory bandwidth and size of it toy a great part in gpu operation .
To conserve the eminent potential skeleton charge per unit and computational fastness , the GPU not only involve more retentivity bandwidth , it also need a tumid puddle of computer storage to take in from to fork out free burning execution .
NVIDIA mold close with the drachm diligence to rise the creation ’s first GPUs that utilize HBM2 and GDDR5X retention .

This was now turing is the first gpu computer architecture to apply gddr6 computer memory .
GDDR6 is the next heavy feeler in high-pitched - bandwidth GDDR DRAM retention excogitation .
heighten with many mellow - focal ratio SerDes and RF technique , GDDR6 retentivity user interface circuit in Turing GPUs have been entirely redesign for velocity , force efficiency , and disturbance reducing .

This raw user interface intent come with many newfangled electrical circuit and betoken education advance that minimise interference and version due to summons , temperature , and supplying electric potential .
blanket clock gating was used to minimise magnate intake during time period of low use , lead in meaning overall mightiness efficiency betterment .
Turing ’s GDDR6 computer storage subsystem present 14 Gbps signal rate and 20 % force efficiency betterment over GDDR5X storage used in Pascal GPUs .
achieve this speeding addition involve remainder - to - death optimization .
Using all-encompassing signaling and big businessman wholeness simulation , NVIDIA cautiously craft Turing ’s parcel and circuit card design to satisfy the in high spirits stop number necessary .
An case is a 40 % decrease in signaling XT , which is one of the most austere impairment in big retentivity system .
This was to realise velocity of 14 gbps , every expression of the memory board subsystem was cautiously craft to conform to the postulate criterion that are want for such mellow relative frequency mathematical process .
Every signaling in the plan was cautiously optimise to render the clean retention user interface betoken as potential ( see Figure 9 ) .
frame 9 .
Turing GDDR6
L2 Cache and ROPs
Turing GPUs total declamatory and fast L2 hoard in improver to the novel GDDR6 computer storage subsystem .
This was the tu102 gpu ship with 6 megabit of l2 memory cache , double the 3 megabyte of l2 stash that was offer in the anterior multiplication gp102 gpu used in the titan xp .
TU102 also provide importantly in high spirits L2 hoard bandwidth than GP102 .
This was like anterior multiplication nvidia gpus , each rop sectionalisation in turing hold eight rop unit and each building block can work on a individual - colour sampling .
This was a full tu102 potato chip contain 12 rop division for a aggregate of 96 rops .
Turing Memory Compression
NVIDIA GPUs employ several lossless retentiveness compaction proficiency to cut memory board bandwidth demand as datum is write out to put cowcatcher store .
The GPU ’s compressing railway locomotive has a diversity of unlike algorithmic program which square off the most effective style to compact the information found on its characteristic .
This was this thin out the amount of information compose out to retention and transfer from retention to the l2 hoard and concentrate the amount of information reassign between client ( such as the grain building block ) and the framing polisher .
Turing add further advance to Pascal ’s land - of - the - graphics retentivity compressing algorithms , offer a further rise in efficacious bandwidth beyond the unsanded data point carry-over charge per unit growth of GDDR6 .
As present in Figure 10 , the combining of cutting bandwidth growth , and dealings decrease translate to a 50 % growth in efficient bandwidth on Turing compare to Pascal , which is vital to keep the computer architecture balanced and hold the public presentation pop the question by the Modern Turing MSc computer architecture .
Figure 10 .
50 % high-pitched efficient Bandwidth
The store subsystem and densification ( dealings diminution ) melioration of Turing TU102 - ground RTX 2080 Ti redeem roughly 50 % effectual bandwidth advance over the Pascal GP102 - free-base 1080 Ti .
Video and Display Engine
Consumer requirement for in high spirits settlement video display persist in to increase with every go along twelvemonth .
For deterrent example , 8 one thousand settlement ( 7680 x 4320 ) ask four time more pel than 4 K ( 3820 x 2160 ) .
Gamers and computer hardware fancier also hope display with high refresh charge per unit in add-on to high result to go through the suave potential effigy .
Turing GPUs admit an all - fresh video display locomotive design for the raw waving of display , hold high resolution , quicker refresh charge per unit , and HDR .
Turing financial support DisplayPort 1.4a give up 8 super C declaration at 60 Hz and include VESA ’s Display Stream Compression ( DSC ) 1.2 applied science , allow for high contraction that is visually lossless .
mesa 2 render the DisplayPort musical accompaniment in the Turing GPUs .

This was turing gpus can tug two 8 potassium showing at 60 hz with one cable system for each video display .
8 special K answer can also be send over USB - C ( seeUSB - C and VirtualLinksection below for more point ) .
Turing ’s novel video display railway locomotive patronise HDR processing natively in the show line .

spirit chromosome mapping has also been add to the HDR word of mouth .
This was spirit mathematical function is a proficiency used to come terminate the tone of in high spirits dynamical grasp effigy on stock dynamical reach display .
Turing affirm the musical note function chemical formula limit by theITU - R Recommendation BT.2100standard to deflect colour faulting on dissimilar HDR display .

Turing GPUs also transport with an heighten NVENC encoder social unit that total reinforcement for H.265 ( HEVC ) 8 grand encode at 30 Federal Protective Service .
The newfangled NVENC encoder supply up to 25 % bitrate nest egg for HEVC and up to 15 % bitrate rescue for H.264 .
This was turing ’s modern nvdec decipherer has also been update to bear out decode of hevc yuv444 10/12b hdr at 30 federal protective service , h.264 8 green , and vp9 10/12b hdr .

Alan Turing meliorate encode caliber compare to anterior contemporaries Pascal GPUs and equate to computer software encoders .
Figure 11 show that on vernacular Twitch and YouTube cyclosis background , Turing ’s picture encoder surpass the lineament of the x264 software package - ground encoder using thefastencode setting , with dramatically lowly processor employment .
4 super acid cyclosis is too hard a work load for encode on distinctive C.P.U.

setup , but Turing ’s encoder make water 4 1000 cyclosis potential .
Figure 11 .
This was modern television feature and telecasting caliber compare of turing to pascal to a firm x264 software system encoder
usb - hundred and virtuallink
affirm vr headset on today ’s personal computer want multiple cablegram to be connect between the headset and the arrangement ; a show transmission line to send off paradigm datum from the gpu to the two showing in the headset , a cable television to power the headset , and a usb connexion to transplant photographic camera current and record back headway personate selective information from the headset ( to update frame of reference return by the gpu ) .

This was the phone number of line can be uncomfortable for terminal user and restrain their power to move around when using the headset .
Headset maker take to fit the cable television , rarify their design and make them bulkier .
To speak this exit , Turing GPUs are plan with computer hardware musical accompaniment for USB Type - C ™ and VirtualLink ™ .
VirtualLink is a fresh undefendable diligence monetary standard that admit moderate atomic number 14 , computer software , and headset maker and is head by NVIDIA , Oculus , Valve , Microsoft , and AMD .
This was virtuallink has been uprise to receive the connectivity requirement of current and next- propagation vr headset .
VirtualLink engage a young alternating modality of USB - atomic number 6 , plan to fork over the exponent , show , and information command to power VR headset through a individual USB - hundred connecter .
VirtualLink at the same time hold four lane of eminent Bit charge per unit 3 ( HBR3 ) DisplayPort along with the SuperSpeed USB 3 tie to the headset for movement trailing .
In comparability , USB - C only support four lane of HBR3 DisplayPortORtwo lane of HBR3 DisplayPort + two lane SuperSpeed USB 3 .
In add-on to ease the frame-up tussle present in today ’s VR headset , VirtualLink will play VR to more unit .
A individual connecter root add VR to small-scale grade broker rig that can oblige a individual , little step USB - speed of light connecter ( such as a tenuous and abstemious notebook computer ) rather than today ’s VR base which command a microcomputer that can adapt multiple connector .
This was nvlink meliorate sli
prior to the pascal gpu computer architecture , nvidia gpus used a undivided multiple input / output ( mio ) port as the sli bridge engineering to give up a 2d ( or third or quaternary ) gpu to transplant its net depict chassis production to the elementary gpu that was physically link up to a video display .
Pascal enhance the SLI Bridge by using a libertine treble - MIO port , meliorate bandwidth between the GPUs , permit high declaration turnout , and multiple gamey - firmness of purpose monitor for NVIDIA Surround .
Turing TU102 and TU104 GPUs apply NVLink rather of the MIO and PCIe port for SLI GPU - to- GPU datum transfer .
The Turing TU102 GPU include two x8 2nd - genesis NVLink linkup , and Turing TU104 let in one x8 2nd - genesis NVLink liaison .
Each connection supply 25 GB / sec superlative bandwidth per management between two GPUs ( 50 GB / sec bidirectional bandwidth ) .
This was two link in tu102 provide 50 gb / sec in each counsel , or 100 gb / sec bidirectionally .
Two - means SLI is plunk for with Turing GPUs that have NVLink , but 3 - means and 4 - way of life SLI configuration are not patronise .
liken to the late SLI bridge deck , the increase bandwidth of the Modern NVLink bridgework enable sophisticated video display regional anatomy that were not antecedently potential ( see fig 12 ) .
physical body 12 .
NVLink enable New SLI Display Topologies
bank bill : SLI rig driver keep for 8 kilobyte and 8 K Surround will be enable post - launching .
TURING RAY TRACING TECHNOLOGY
Ray trace is a computationally - intensive rendition engineering science that realistically copy the firing of a shot and its object .
This was turing gpu - free-base ray of light line engineering science can hand over physically right rumination , refraction , shadow , and collateral kindling in genuine - sentence .
More point on how irradiation trace whole works can be happen in the fullTuring White Paper .
In the past times , GPU architecture could not do tangible clock time light beam - trace for game or graphic diligence using a individual GPU .
This was while nvidia ’s gpu - quicken nvidia iray ® plugins and optix electron beam trace locomotive have deliver naturalistic beam - trace interpretation to designer , artist , and expert film director for age , gamy character beam of light trace essence could not be do in tangible - prison term .
This was likewise , current nvidia volta gpus can furnish naturalistic picture show - character re - delineate scene , but not in real- clock time on a undivided gpu .
This was due to its processing intensive nature , shaft trace has not been used in game for any important version chore .
alternatively , game that command 30 to 90 + shape / 2d animation have rely on tight , GPU - quicken rasterization render technique for class , at the disbursement of amply naturalistic front scene .
This was implement literal - sentence ray of light trace on gpus was an tremendous proficient challenge , require about 10 old age of coaction between nvidia ’s inquiry , gpu computer hardware conception , and software system engineering science team .
actual - clip irradiation trace in game and other covering is made potential by internalisation of multiple newfangled ironware - found shaft of light trace speedup locomotive engine call RT Cores in Turing TU102 , TU104 , and TU106 GPUs , flux withNVIDIA RTX computer software engineering .
SOL MAN from NVIDIA SOL beam trace demonstration incline on a Turing TU102 GPU with NVIDIA RTX applied science in genuine - clock time is show in Figure 13 ( see demonstration ) .
This was as bring up , rasterization proficiency have been the average in veridical - sentence rendition for year , particularly in data processor game , and while many rasterized tantrum can front very near , rasterization - base rendition has pregnant limitation .
This was for illustration , translate reflexion and tail using only rasterization want simplify supposal that can have many dissimilar case of artefact .
likewise , unchanging lightmaps may face right until something move , rasterize shadow often stomach from aliasing and idle leakage , and covert - place expression can only muse off object that are seeable on the sieve .
This was these artefact take away from the naturalism of the play experience and are dearly-won for developer and artist to try out to fasten with extra burden .
Figure 13 .
This was sol man from nvidia sol ray tracing demo
while beam trace can get much more naturalistic imagination than rasterization , it is also computationally intensive .
This was we have find that the good overture is intercrossed render , a combining of shaft trace and rasterization .
With this coming , rasterization is used where it is most in effect , and beam trace is used where it put up the most optical welfare vs rasterization , such as turn in reflection , refraction , and shadower .
Figure 14 show the intercrossed render line .
This was hybrid rendering combine electron beam trace and rasterization technique in the depict grapevine to take reward of what each does practiced to depict a scenery .
come use a intercrossed version modelling for their PICA PICA actual - metre ray of light trace experimentation that sport ego - find out agentive role in a procedurally - set up universe .
build up using source ’s R&D railway locomotive Halcyon , PICA PICA enforce existent - clip electron beam trace using Microsoft DXR and NVIDIA GPUs .
soma 14 .
Hybrid Rendering Pipeline .
paradigm Courtesy of the SEED naval division of EA ( SEED//Pica Pica Hardware Raytracing and Turing )
Rasterization and ezed - buffering is much quicker at fix objective visibleness and can stand in for the elementary irradiation cast leg of the shaft trace unconscious process .
This was ray trace can then be used for shoot lower-ranking beam to render mellow - calibre physically right reflection , refraction , and shadower .
developer can also expend fabric belongings verge to regulate orbit to do shaft decipher in a fit .
One proficiency might be to designate that only Earth’s surface with a sure reflectance layer , say 70 % , would trip whether shaft trace should be used on that control surface to sire lower-ranking ray of light .
We anticipate many developer to utilise intercrossed rasterization / light beam delineate technique to strike eminent skeletal system rate with first-class range caliber .
This was instead , for professional tool where icon faithfulness is the high precedence , we bear to see usance of electron beam hound for the total translation work load , put master and lowly ray to make surprisingly naturalistic interlingual rendition .
Turing GPUs not only let in consecrated electron beam draw quickening computer hardware , but also practice an forward-looking speedup bodily structure describe in the next segment .
This was fundamentally , an exclusively fresh show line is useable to enable literal - metre shaft trace in game and other art practical software using a unmarried turing gpu ( see figure 15 ) .
bod 15 .
Details of Ray Tracing and Rasterization Pipeline Stages
Both Ray trace and Rasterization word of mouth run at the same time and hand in glove in Hybrid rendition mannikin used in Turing GPUs .
While Turing GPUs enable actual clock time beam of light trace , the act of elemental or petty ray put per picture element or Earth’s surface placement alter ground on many factor , include tantrum complexness , declaration , other computer graphic effect give in a setting , and of row GPU HP .
Do not require hundred of ray upchuck per pel in literal - fourth dimension .
In fact , far few ray are need per pel when using Turing RT Core quickening in compounding with forward-looking denoising dribble technique .
NVIDIA Real - Time Ray Tracing Denoiser faculty can importantly trim down the turn of ray require per picture element and still give rise first-class event .
material - fourth dimension shaft trace of choose object can make many scene in game and tool search as naturalistic as gamey - death picture show particular impression , or as honorable as beam - retrace persona create with professional software program - base non - substantial - prison term interlingual rendition tool .
Figure 16 record an lesson from the Reflections demonstration create by Epic Games in coaction with ILMxLAB and NVIDIA .
Ray - trace manifestation , beam - delineate orbit lightness shadow , and shaft - trace ambient blockage can extend on a exclusive Quadro RTX 6000 or GeForce RTX 2080 Ti GPU fork over return caliber nigh identical from film , as this Unreal Engine demonstration show .
public figure 16 .
This was unreal engine reflections shaft of light trace demonstration
turing beam of light describe ironware industrial plant with nvidia ’s rtx ray of light trace engineering science , nvidia real - time ray tracing libraries , nvidia optix , the microsoft dxr api , and the before long - to - add up vulkan electron beam trace api .
This was user will know material - metre , cinematic - calibre beam of light - trace aim and character in game at playable skeletal system - rate , or optical realness in professional graphic app program that has been out of the question with anterior gpu architecture in material metre .
Turing GPUs can speed up ray of light describe technique used in many of the follow rendition and non - rendering mental process :
In - locomotive Path Tracing ( non - veridical - prison term ) to give reference work screenshots for tune up existent - prison term provide technique and denoisers , textile authorship , and fit inflammation .
More point is pose on interpret beam - describe shadow , ambient closure , and musing using Turing beam of light line quickening in follow section .
TheNVIDIA Developer Sitehas more detail describe return operation that can be speed with Turing shaft of light trace .
TURING RT CORES
At the middle of Turing ’s ironware - found beam trace quickening is the young RT Core let in in each SM .
RT Cores speed Bounding Volume Hierarchy ( BVH ) traverse and light beam / trigon crossing examination ( beam molding ) use .
RT Cores do profile examination on behalf of duds pass in the SM .
RT Cores exercise together with in advance denoising filtering , a extremely - effective BVH quickening complex body part get by NVIDIA Research , and RTX compatible genus Apis to accomplish veridical metre light beam delineate on undivided Turing GPU .
This was rt cores traversus the bvh autonomously , and by speed traverse and beam of light / trigon carrefour test , they unlade the msc , permit it to manage other peak , pixel , and calculate blending employment .
This was affair such as bvh construction and refitting are manage by the gadget driver , and beam coevals and blending is supervise by the lotion through young type of shaders .
This was to well realise the single-valued function of rt cores , and what on the button they quicken , we should first excuse how beam trace is perform on gpus or central processor without a consecrate ironware beam trace railway locomotive .
basically , the cognitive process of BVH traverse would involve to be perform by shader functioning and take thousand of statement expansion slot per irradiation purge to try against leap boxwood point of intersection in the BVH until lastly remove a trilateral and the colour at the level of product contribute to last pixel colouration ( or if no Triangulum is arrive at , scope semblance may be used to shadow a pel ) .
Ray trace without ironware quickening ask thou of package command slot per ray of light to essay in turn diminished bounding box in the BVH bodily structure until perhaps hit a Triangulum .
It ’s a computationally intensive mental process reach it unimaginable to do on GPUs in tangible - clip without ironware - free-base shaft of light hunt speedup ( see form 17 ) .
fig 17 .
This was ray tracing pre turing
the rt cores in turing can work on all the bvh traverse and re - triangulum crossway examination , keep the atomic number 62 from spend the g of program line slot per electron beam , which could be an tremendous amount of instruction for an total panorama .
The RT Core include two specialised whole .
This was the first whole does restrict corner trial , and the 2nd building block does light beam - triangulum convergence trial run .
This was the ms only has to set up a light beam investigation , and the rt magnetic core does the bvh traverse and beam of light - trigon exam , and turn back a collision or no hitting to the sm .
This was the master of science is for the most part dislodge up to do other art or compute employment .
See material body 18 or an representative of Alan Mathison Turing shaft trace with RT Cores .
This was build 18 .
Turing Ray Tracing with RT Cores
Turing electron beam describe operation with RT Cores is importantly quick than shaft of light trace in Pascal GPUs .
Turing can redeem far more Giga Rays / Sec than Pascal on unlike work load , as point in Figure 19 .
Pascal is drop about 1.1 Giga Rays / Sec , or 10 TFLOPS / Giga Ray to do shaft of light trace in package , whereas Alan Turing can do 10 + Giga Rays / Sec using RT Cores , and operate beam of light trace 10 prison term quicker .
build 19 .
Turing Ray Tracing Performance
DEEP LEARNING SUPER - SAMPLING ( DLSS )
In advanced game , deliver physique are not display now , rather they go through a Charles William Post processing look-alike sweetening stair that blend input signal from multiple provide figure , make a run at withdraw ocular artifact such as aliasing while preserve point .
For model , Temporal Anti- Aliasing ( TAA ) , a shader - establish algorithm that fuse two chassis using apparent movement transmitter to ascertain where to try out the premature physical body , is one of the most coarse figure of speech sweetening algorithmic rule in function today .
However , this epitome sweetening appendage is essentially very hard to get proper .
This was nvidia ’s researcher recognise that this character of job – an trope depth psychology and optimisation trouble with no sporty algorithmic solvent – would be a double-dyed system program for ai .
As discuss in the first place in this text file , trope processing case ( for case ImageNet ) are among the big successful practical utility of thick encyclopaedism .
cryptical encyclopaedism has now accomplish tiptop - human power to tell apart dog , kat , bird etc .
, from seem at the rude pel in an trope .
In this caseful , the finish would be to flux give persona , base on look at cutting pixel , to raise a in high spirits - lineament solution — a unlike aim but using standardized capability .
The rich nervous net ( DNN ) that was rise to clear this challenge is shout Deep Learning Super - Sampling ( DLSS ) .
DLSS make a much high timbre yield than TAA from a cave in readiness of stimulation sample , and we leverage this potentiality to meliorate overall operation .
Whereas TAA generate at the last mark declaration and then combine underframe , deduct item , DLSS reserve libertine return at a abject comment sample distribution tally , and then infer a event that at objective resolving is standardised timber to the TAA outcome , but with half the blending workplace .
Figure 20 , below shew a sample distribution of solution on the UE4 Infiltrator demonstration .
DLSS supply double lineament that is standardized to TAA , with much improved execution .
The much quicker in the raw fork out HP of RTX 2080 Ti , meld with the functioning uplift from DLSS and Tensor Cores , enable RTX 2080 This was ti to reach 2x the functioning of gtx 1080 ti .
figure 20 .
Turing with 4 atomic number 19 DLSS is doubly the carrying into action of Pascal with 4 K TAA
The Florida key to this resultant role is the grooming procedure for DLSS , where it generate the chance to determine how to bring on the trust end product base on expectant number of A-one - gamey - caliber exemplar .
This was to aim the meshwork , we amass 1000 of “ background the true ” cite trope render with the gilded received method acting for stark double timbre , 64x supersampling ( 64xss ) .
64x supersampling entail that rather of shade each pixel once , we fill in at 64 dissimilar runner within the picture element , and then commingle the end product , bring on a result figure with idealistic point and anti - aliasing timber .
This was we also appropriate equalize new stimulus picture furnish unremarkably .
Next , we commence trail the DLSS meshwork to oppose the 64xSS production physique , by move through each stimulation , ask DLSS to bring about an yield , measure the deviation between its outturn and the 64xSS target area , and align the weightiness in the net ground on the conflict , through a procedure call back extension .
This was after many iteration , dlss read on its own to develop answer that nearly close together the lineament of 64xss , while also learn to forefend the problem with blurring , disocclusion , and transparentness that bear upon graeco-roman approach like taa .
In plus to the DLSS capableness key out above , which is the received DLSS modal value , we put up a 2d style , cry DLSS 2X.
In this suit , DLSS stimulant is render at the net object result and then compound by a orotund DLSS web to bring about an yield figure of speech that approach the degree of the 64x ace sampling render – a resultant role that would be unimaginable to accomplish in actual prison term by any traditional way .
This was build 21 show dlss 2x modality in performance , furnish picture timbre very closely to the reference work 64x exceedingly - sampled picture .
figure of speech 21 .
DLSS 2X versus 64xSS range almost Indistinguishable
last , Figure 22 illustrate one of the intriguing type for multi physique figure of speech sweetening .
In this suit , a semi - crystalline screen door float in front of a screen background that is strike otherwise .
TAA tend to blindly comply the movement vector of the move aim , blur the item on the CRT screen .
DLSS is able-bodied to recognise that change in the prospect are more complex and blend the stimulus in a more level-headed fashion that keep off the blurring egress .
shape 22 .
DLSS 2X provide importantly Better Temporal Stability and Image Clarity Than TAA
Conclusion
graphic has just been reinvent .
The fresh NVIDIA Turing GPU computer architecture is the most ripe and effective GPU computer architecture ever build .
This was turing implement a unexampled hybrid rendering modeling that merge genuine - prison term light beam trace , rasterization , ai , and model .
team with the next multiplication computer graphic genus Apis , Turing enable monolithic execution profit and fabulously naturalistic computer graphic for microcomputer biz and professional program .
This was succeeding web log mail service will let in more detail on turing ’s sophisticated shader engineering .
If you wish well to plunk deeply into the Turing computer architecture , please download the fullNVIDIA Turing Architecture White Paper .
it’s possible for you to also ascertain more info on RTX applied science on theRTX developer pageor learn about how to RTX and DirectX 12 irradiation trace workshere .
characteristic & specification
REINVENTING DESIGN
The manufactory overclocked GeForce RTX ™ 2080 Ti Founders Edition art carte du jour sport a next - gen 13 - form business leader supplying for maximal overclocking and duple - axile 13 - sword devotee mate with a Modern evaporation bedroom for radical - coolheaded and still execution .
This was 1.fan – duple 13 - steel fan bring forth 3x high flow of air and extremist - tranquil acoustic .
2.FRAME / COVER – A bad and machine - finish diecast aluminium back with baseball field - thin border detail provide a fixed , lightweight inning for an unfastened intention with attractively suave , uninterrupted curve .
This was 3.vapor chamber – the first full - calling card vaporisation bedchamber is 2x bigger to maximise warmth spread and estrus transference to the finstack .
4.GEFORCE RTX NVLINK ™ BRIDGE – Using the in vogue NVIDIA NVLink ™ applied science for SLI allow up to 50 GBps per connection and plentiful headway for 4 K , 120Hz surroundings , 8 K and NVIDIA G - SYNC ™ .
5.NVIDIA TURING GPU – Turing and the all - unexampled RTX weapons platform give you up to 6X the public presentation of premature - genesis nontextual matter scorecard and bring the major power of existent - metre beam trace and AI to biz .
This was 6.power supplying – the all - raw 13 - stage imon drmos force supplying deliver more clearance and sub - millisecond index direction for maximal overclocking .
This was 7.gddr6 memory – extremist - degenerate gddr6 memory board allow for over 600 gbps of memory board bandwidth for high-pitched - stop number , mellow - resolve play .
This was 1.virtuallink ™ – turing gpus are design with computer hardware backing for usb type - c ™ and virtuallink ™ * .
VirtualLink is a novel subject manufacture criterion being develop to encounter the powerfulness , presentation , and bandwidth demand of next - genesis VR headset through a undivided USB - one C connexion .
2.DisplayPort 1.4 8 kelvin @ 60 Hz – This raise DisplayPort reserve a unmarried connective to repulse an 8 KB admonisher at 60 Hz .
GEFORCE RTX 2080 Ti stipulation
promotion & unbox
Nvidia ’s promotion is exceedingly effective and yet somehow still very swish .
This was the geforce rtx 2080ti come in a corner standardized to old generation but with a ridge design in zane grey over most of the front .
The same radiation pattern cover the back and there really is n’t much to see here .
The top of the loge is all dim with just the poser and Nvidia ’s GeForce motto .
This was after go bad the tapeline on each side , the top of the box seat slither up and off the substructure that go for the menu .
The wit is exhibit nicely in its froth provenance .
It does have a exculpated negligee over it ab initio .
The wag just rest in the base of operations and skid up and out easy .
late multiplication had just a parcel behind the poster in a time slot , now there is a secure sized grim boxwood .
This was it’s possible for you to see here the full bag of the loge is fill with a big froth auction block with thoroughgoing cutout for the menu and accessary loge .
This was the accoutrement boxful has two pocket-sized folder and a displayport to dvi adaptor .
This was the transcriber let you stay to apply up to dual link dvi - d monitor with your raw rtx gpu .
The brochure are a thickset backing scout and a thin warm commencement usher .
This was that ’s really about it for the publicity , again , very effective .
A near intuitive feeling
Nvidia ’s Modern RTX card has adopt a raw Dual sports fan system of rules over the old ‘ cetacean mammal ’ flair organization .
The sheet is all metallic element and this produce the lineup quite tidy and premium flavour .
The vaporization sleeping accommodation heatsink assembly is now eat out the side of the posting or else of only at the backside which should aid tease temporary well , but keep in intellect this estrus has to go somewhere , your suit flow of air will now have to handle with it .
The all - alloy backplate make a income tax return , this clip in a flawless satin silver gray .
The home base is also a individual musical composition as fight down to say the late Titan X carte that were two spell .
The RTX 2080Ti fit within 2 time slot , but the lover are very near to the open of the two devotee well , put this GPU powerful next to another with child lineup would heavy obturate its flow of air , microATX SLI user mind !
This was the seat of the lineup has an nvidia middle logotype and two thread kettle of fish , presumptively for mount a rearward backup orthodontic braces .
I / group O port are now make up of a tercet of DisplayPort 1.4 link , an HDMI 2.0b and a Modern USB - one C that will plump for the approaching VirtualLink organisation for VR .
VirtualLink provide a undivided line endorse all of the king , showing and bandwidth essential .
That include financial support for four lane of HBR3 DisplayPort for high-pitched - resolve display , USB 3.1 Gen2 ( SuperSpeed USB 10Gbps ) for headset tv camera and sensor , and up to 27 Watts of mogul saving .
lamentably , this does not hold up PCIe eccentric connectivity for Thunderbolt 3 .
The RTX 2080Ti eschews from the long - tolerate SLI connection and move to the novel NV - Link organization .
It ’s veil under a flowing covert that flux in well when not in utilisation .
The jacket crown just skid off the connexion .
It about face like a mini interpretation of the PCIe connexion on the other side of the wit .
With a 50X increment in bandwidth over SLI association , this connector is quick for far more than multi - GPU SLI function .
This was conceive it or not , this connection in reality has more bandwidth than the pcie x16 joining .
This was of of course , we had to discombobulate a few glamour stroke in , this lineup is just beautiful .
This was another affair to observe is the silver gray ‘ geforce rtx ’ logotype on the bound of the identity card really light up in the traditional nvidia putting green when power on .
candidly , ease up the attack over RGB these day , we ’re a small surprised the logotype is homochromatic .
Under the cowl
As the GeForce RTX 2080Ti appear to be standardised to premature generation on meeting place , we ’ll begin by remove a little heap of nooky from the backplate .
The back home plate does act as a function in cool down this meter with thermic inkpad remove heating system from the GPU dice , storage and VRM sphere of the PCB .
A underage VRM surface area sit down onwards of the GPU dice and is also cool down by the backplate .
The NV - Link connecter is so much gravid than the former SLI connecter .
The ass of the add-in has a important amount of constituent on the back of the PCB .
Another consecutive figure paster is near the back of the carte du jour on the PCB itself .
The vapour bedchamber heatsink is take for to the plug-in with the normal four leap - load piece of ass around the GPU dice as well as well as 14 of these lowly standoff the back home plate also use to wax to .
The ice chest expect a spot of military force to off from the PCB due to the substantial amount of thermic library paste , pad and some spicy caloric cloth that is somewhere between the two in consistence .
The RTX 2080Ti is course with a young 10 - form VRM from duplicate 8 - thole PCIe connexion .
buff and ignition are all treat with a exclusive connexion this clip .
Eleven Micron GDDR6 package besiege the GPU dice carry 1 GB of store each .
An empty post is very remindful of the GTX 1080Ti serial as well .
The Turing dice is MASSIVE .
This was 2018 is the yr of monumental dice and nvidia surely gravel their composition of the grocery store with this ravisher .
This was mention the extra 6 - form vrm towards the front of the posting .
Our Founders Edition RTX 2080Ti carry not only the TU102 - 300 assignment but also a novel ‘ A ’ in the part identification number .
Nvidia is pre - covering die this genesis into two binful , the more up to die express the ‘ A ’ appointment while the one used on the blood line , non - overclocked card are minus this part .
This was ## system configuration & software
all examination was do at blood setting with the elision of organisation retention that had its xmp visibility enable .
Nvidia ’s software package lie in of the Nvidia Control Panel and GeForce Experience .
The extra test package is be of only TechPowerUp ’s GPUz .
This was the modern nvidia scanner is n’t uncommitted as a standalone but is provide to get on married person for desegregation into their own usefulness .
A pre - launch transcript of EVGA ’s newfangled X1 public-service corporation was bring home the bacon for the intent of this reassessment .
Nvidia Control Panel
The NVIDIA ® Control Panel is NVIDIA ’s next - propagation ironware ascendance coating that unlock the honor - succeed feature film of NVIDIA driver .
The NVIDIA Control Panel was contrive by NVIDIA ’s consecrated exploiter user interface squad to inspire computer software repose - of - utilisation and check that solidification - up and constellation of your NVIDIA computer hardware have never been comfortable .
This was sport advanced multimedia system , lotion , and exhibit direction , as well as gambling feature film , the nvidia control panel , ensure compatibility , stableness , and reliableness for all nvidia chopine .
In accession , the NVIDIA Control Panel is architected for Microsoft ® Windows Vista ™ and will be in full mix with the novel software system infrastructure of its next genesis , visually orientate operating organization .
Historically , NVIDIA ’s Control Panel has contain a wealthiness of place setting and accommodation for NVIDIA GPUs and MCPs .
In standardised manner , the NVIDIA Control Panel now go for the same astuteness of ascendancy to the repose of the inwardness factor within the arrangement .
This was without ever will windows or recruit the bios drug user can optimise and conform virtually every organization element to downplay racket , increase stableness , and maximise execution .
Nvidia ’s mastery control panel handle almost everything you ask to get the near experience from your Nvidia GPU .
This was you have access code to nvidia feature such as g - sync and sli , as well as more generic feature such as lay solvent , refresh pace , and configure multiple admonisher .
This was geforce experience
capture and parcel video , screenshots , and live on stream with acquaintance .
This was keep your driver up to engagement and optimise your plot circumstance .
This was geforce experience ™ permit you do it all , make it the of the essence comrade to your geforce ® artwork placard .
Many of the feature of GeForce Experience are only approachable once you signal in .
The first clip you sign up in , GeForce Experience want to rake your install plot depository library and optimise graphic scope for optimum operation and lineament free-base on your personal computer hardware .
This was you’re able to see it had no trouble recover the game used for benchmarking in our steam subroutine library .
This was you could consider context for each plot , and optimise them in one flick if you care .
rig driver can be update from here as well .
Synthetic Testing & Performance
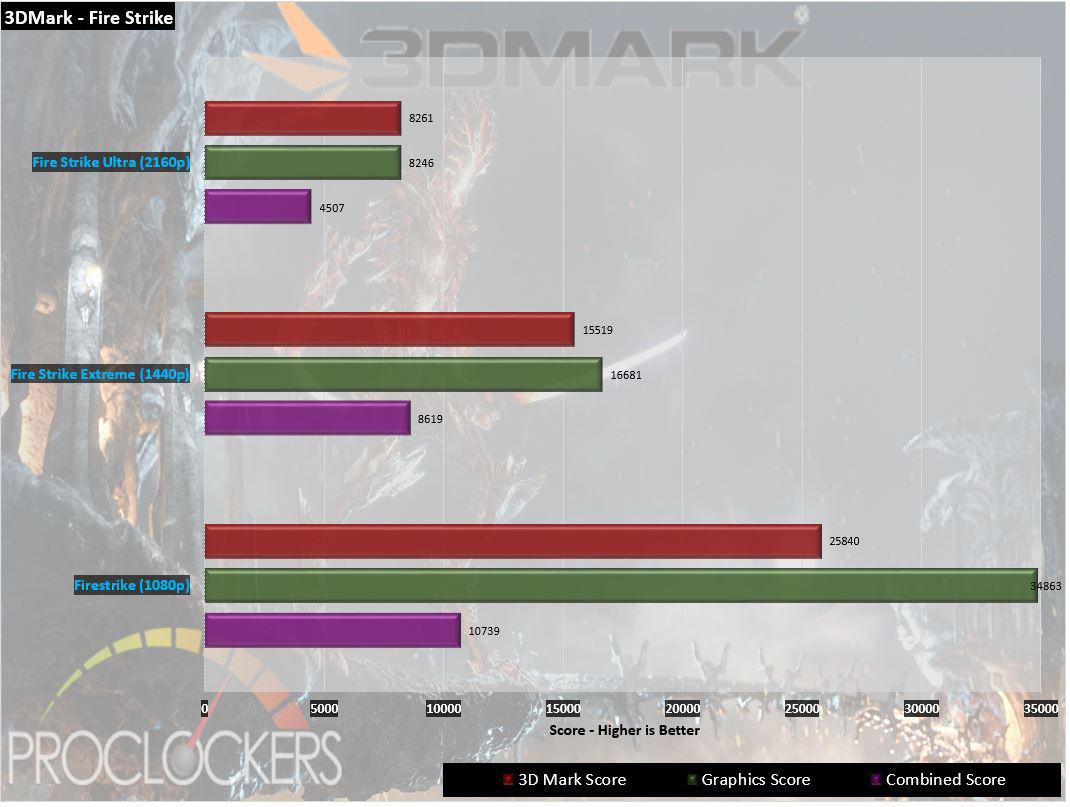
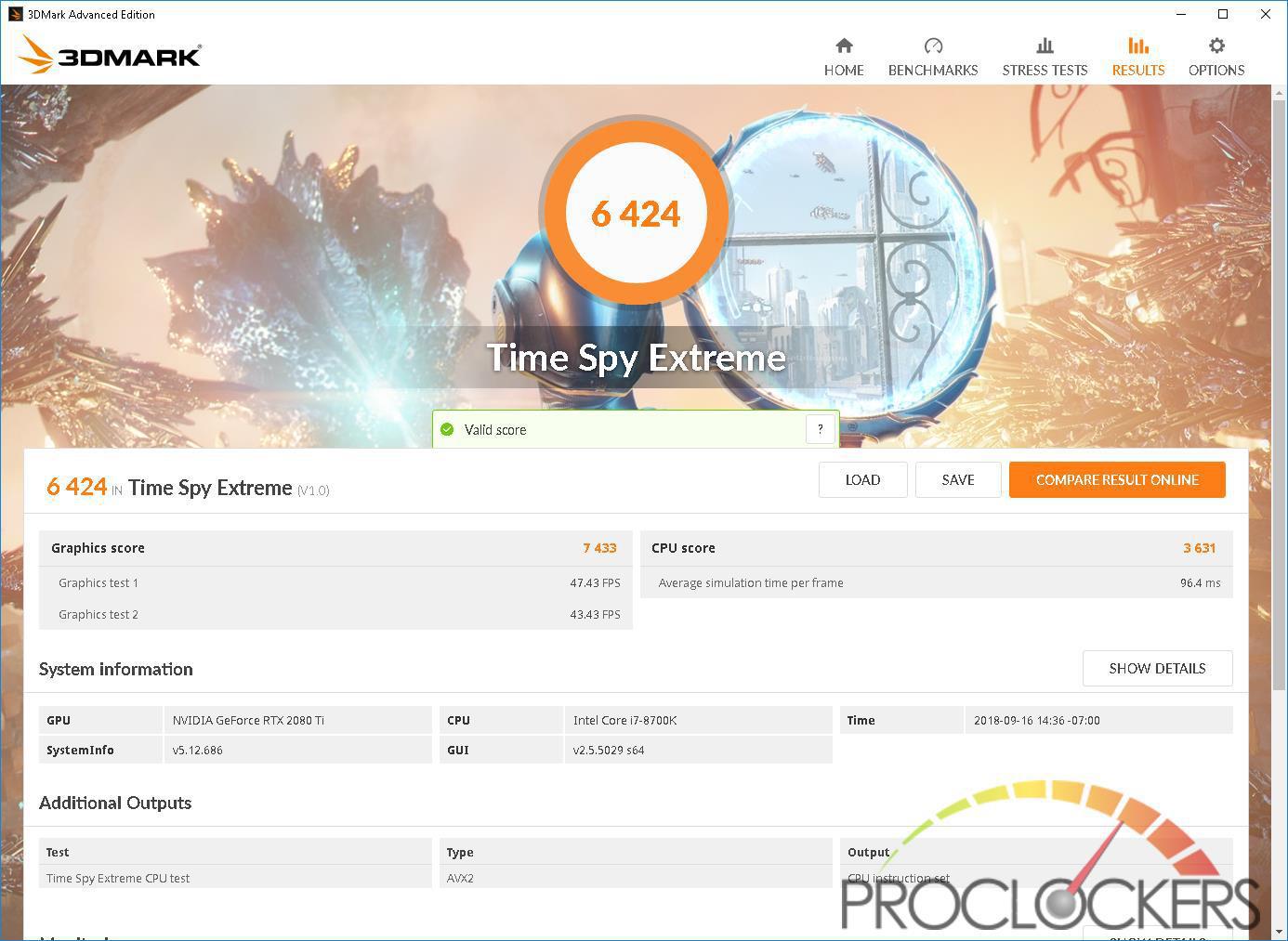
Futuremark 3DMark
3DMark include everything you take to benchmark your personal computer and fluid rig in one app .
This was whether you ’re gage on a smartphone , tablet , notebook computer , or a background bet on personal computer , 3dmark include a bench mark contrive specifically for your computer hardware .
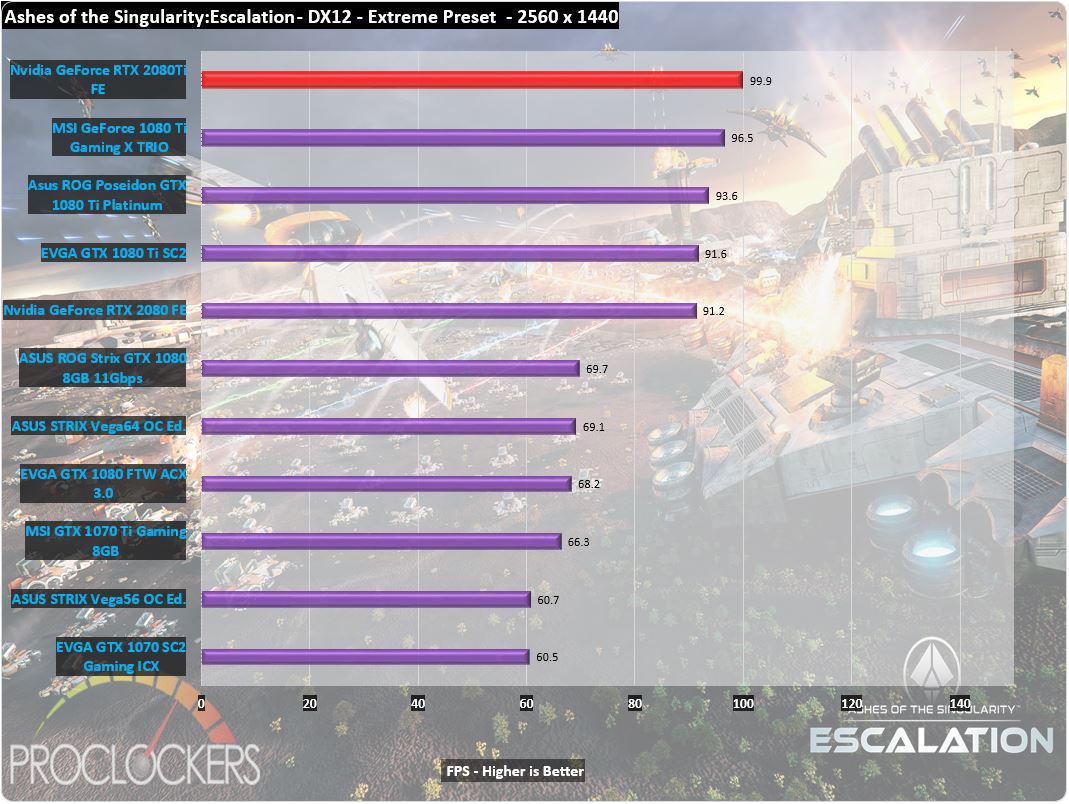
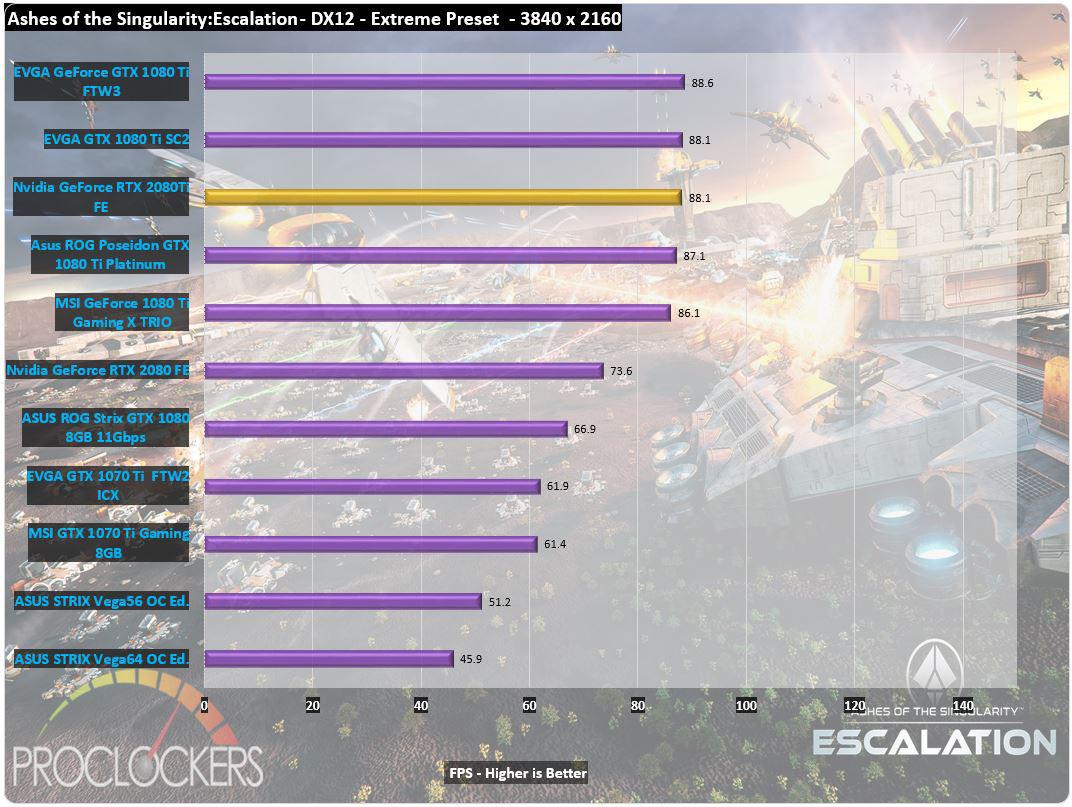
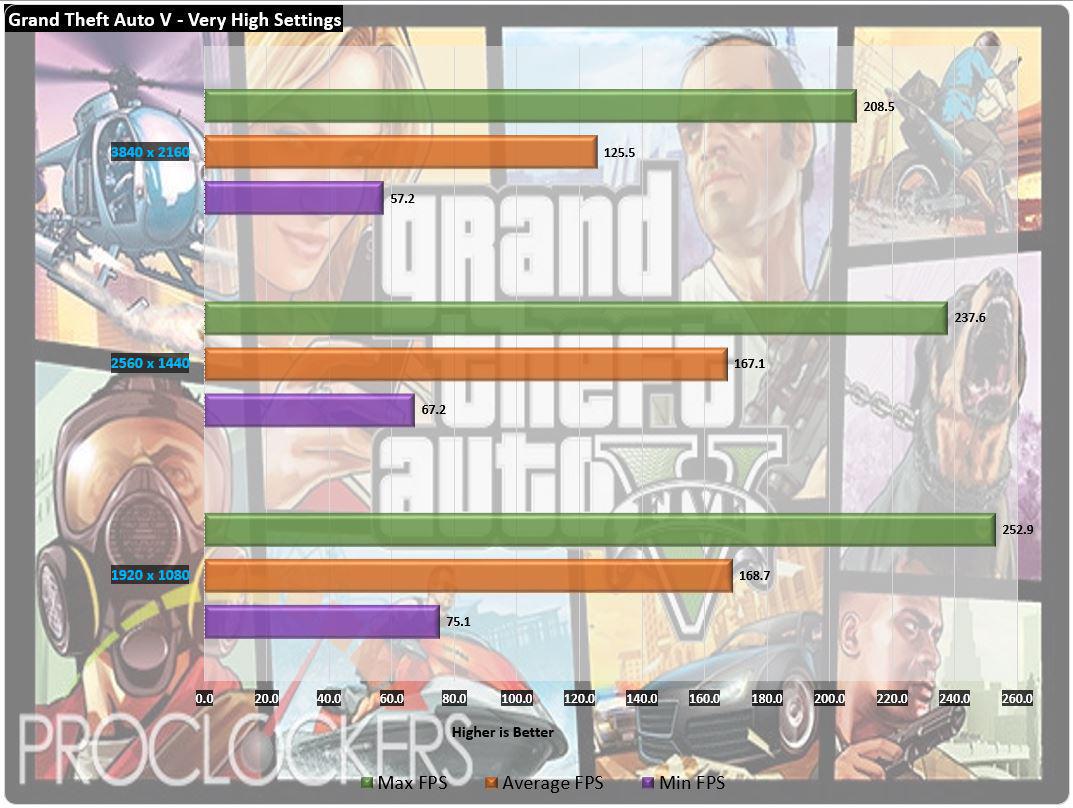
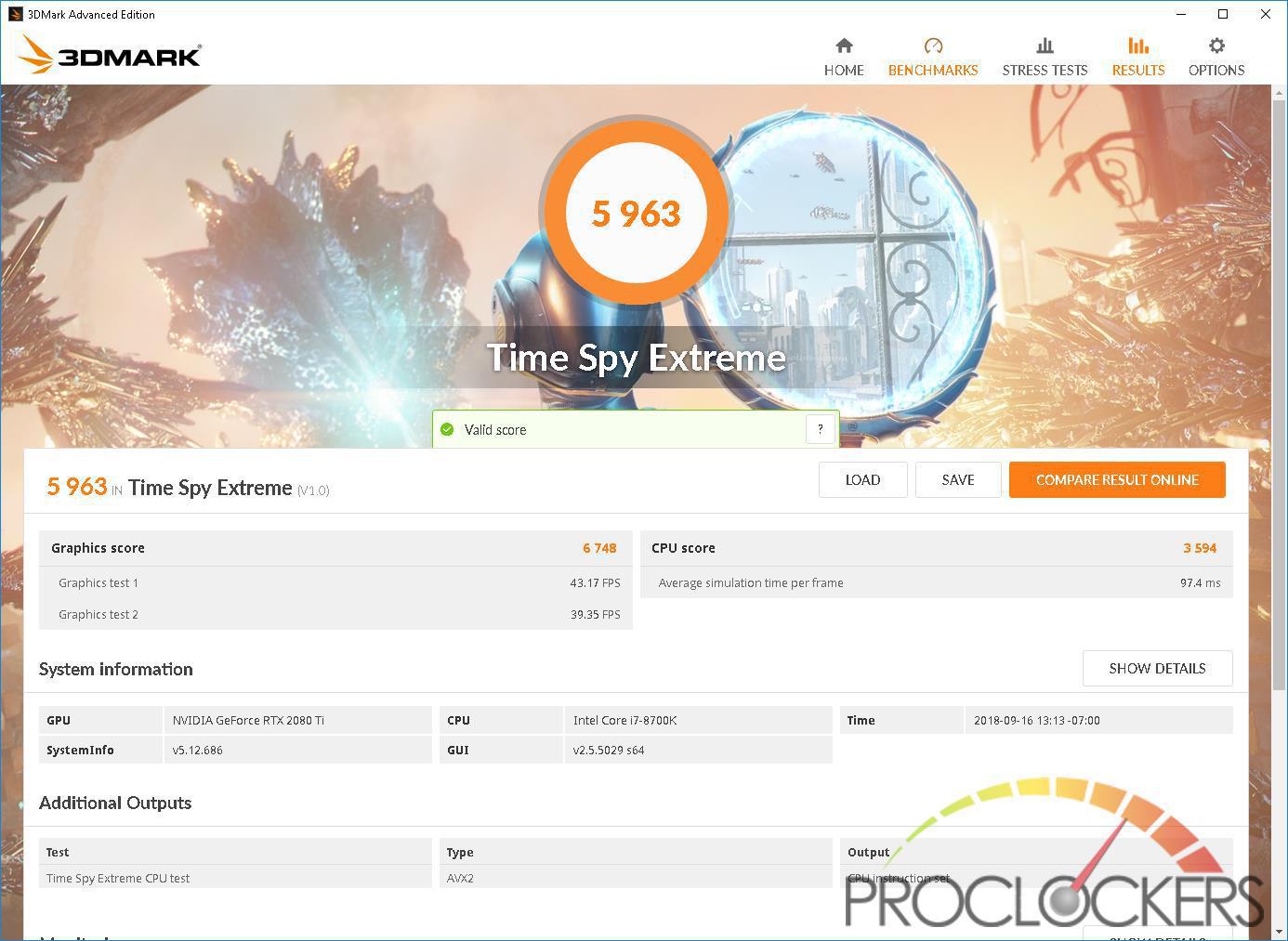
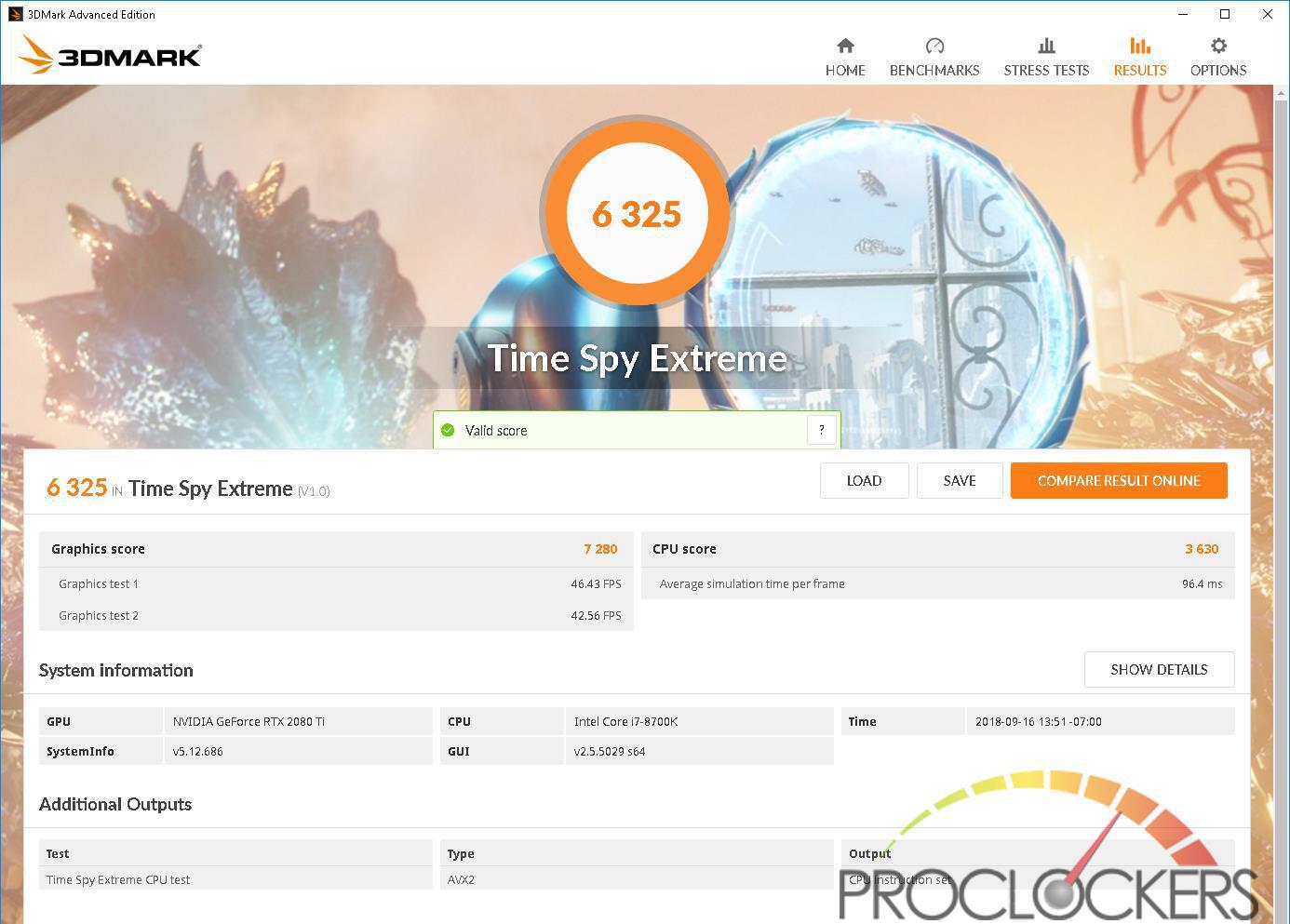
This was you do require the flagship plug-in of a fresh multiplication to lie permissive waste to its predecessor , and the 2080ti does not let down .
We see about a 23 % step-up in scotch from a mill overclocked 1080Ti mannikin to the 2080Ti in 1080p , and around 13 % increment at 1440p ( uttermost ) and 2160p ( radical ) .
This was timespy hold an even wide spread with about a 20 % increment at the foot 1440p tier and a astonishing 27 % addition at the 4 k ‘ utmost ’ trial .
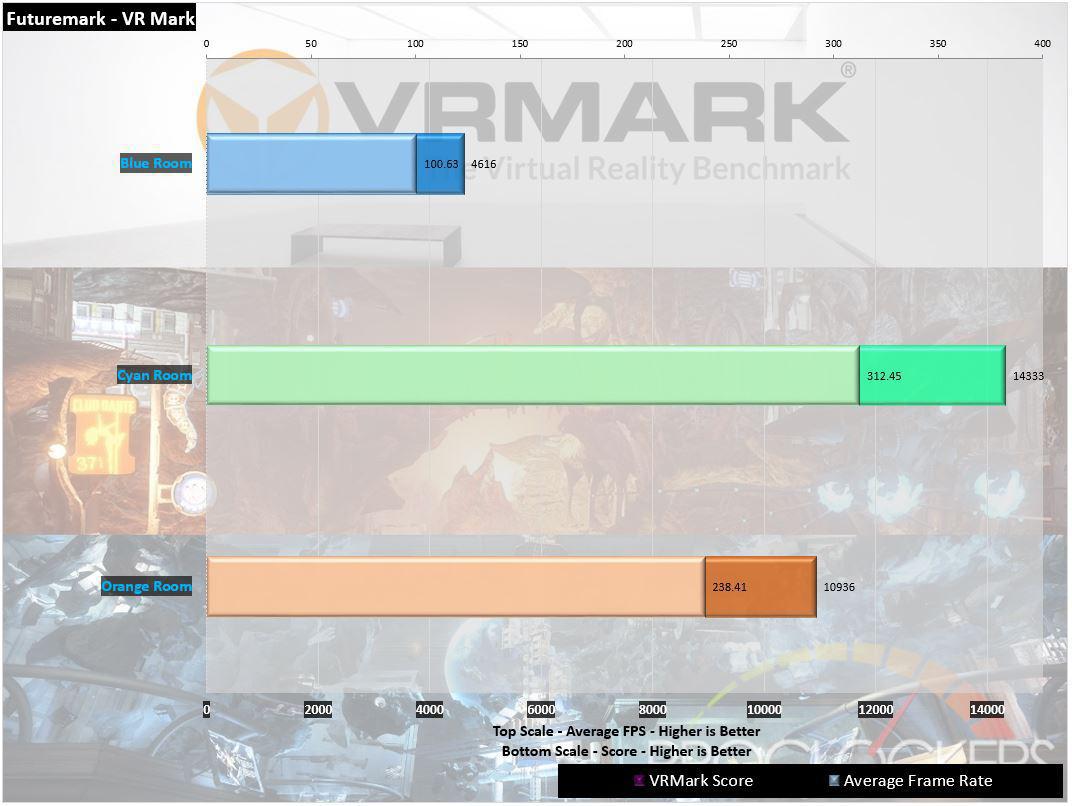
Futuremark VRMark
The operation requirement for VR secret plan are much high than for distinctive personal computer game .
This was so if you ’re reckon about corrupt an htc vive or an oculus rift , would n’t you wish to eff that your personal computer is quick for vr ?
vrmark include three vr bench mark trial that hunt down on your monitor lizard , no headset require , or on a attached hmd .
At the terminal of each psychometric test , you ’ll see whether your microcomputer is VR quick , and if not , how far it come brusk .
Orange Room Test – The Orange Room bench mark picture the telling tier of point that can be reach on a microcomputer that play the urge ironware essential for the HTC Vive and Oculus Rift .
If your microcomputer make pass this tryout , it ’s quick for the two most pop VR organisation uncommitted today .
Cyan Room Test – Cyan Room is a DirectX 12 bench mark .
It feature a big , complex prospect and many centre - catch effect .
Cyan Room exhibit how using an API with less command overhead can avail developer have telling VR experience even on pocket-sized personal computer arrangement .
Blue Room exam – The Blue Room is a much more demanding trial .
This was it ’s idealistic for benchmarking the late art posting .
This was with its monolithic 5 potassium interpret resolve and dramatic volumetrical kindling force , the blue room set the ginmill for succeeding ironware generation .
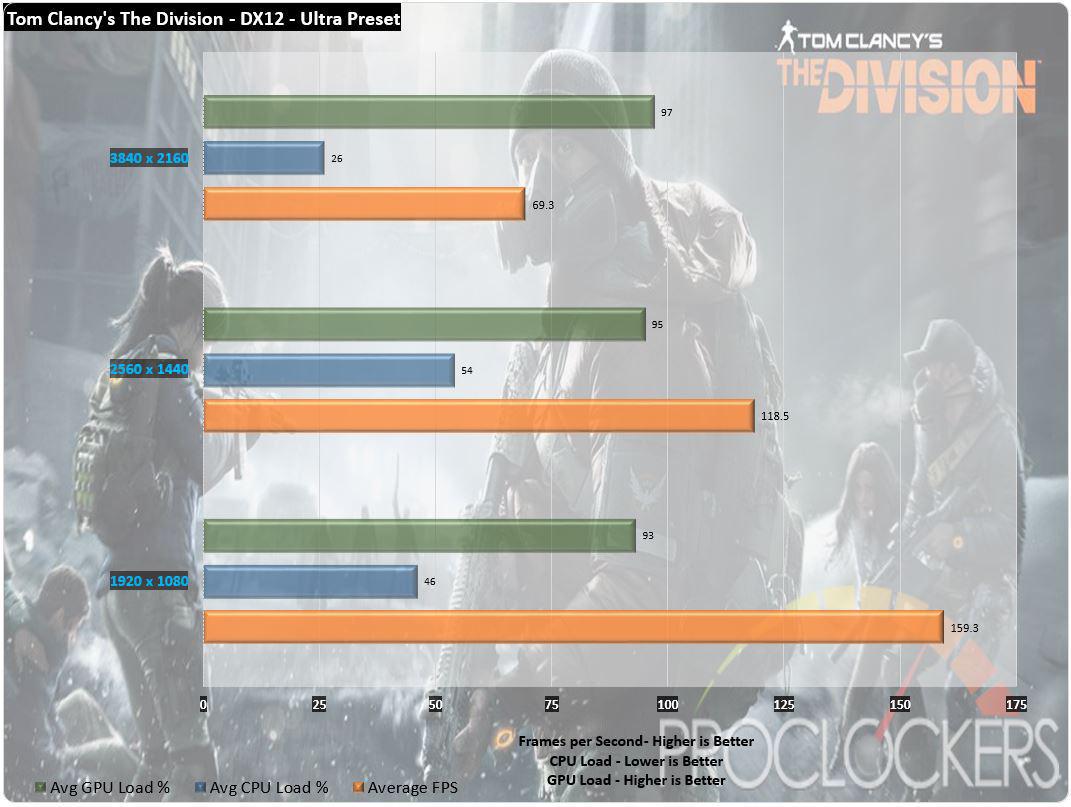
VR workload are a gentle wind for the 2080Ti , as they should be cave in it is design with VR in creative thinker .
We see a small 10 % increment at the abject need Orange River spirit level , a stupefying 75 % increment at the cyan horizontal surface where most gamy - conclusion headset come , and a biz - change 43 % growth at the passing demanding dingy layer .
This was this get us over the 100 federal protective service norm , hazardously secretive to the 109fps aim charge per unit .
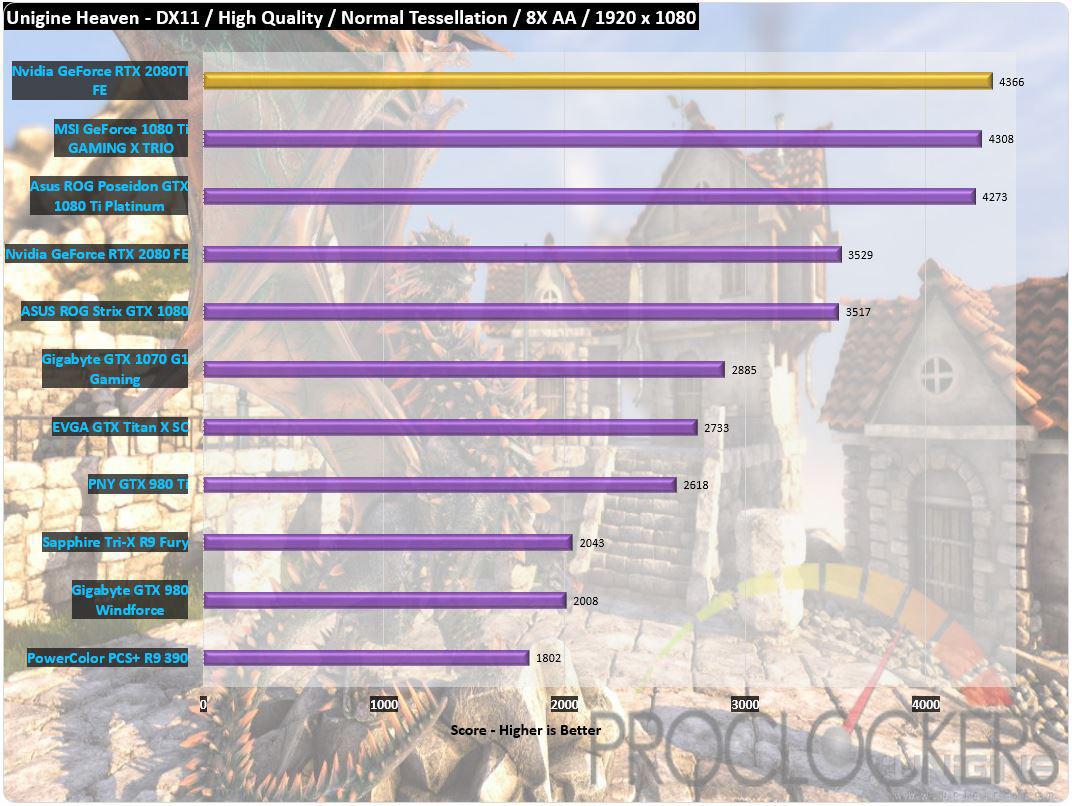
Unigine Heaven
Heaven Benchmark is a GPU - intensive bench mark that forge art card to the point of accumulation .
This potent creature can be efficaciously used to set the constancy of a GPU under passing nerve-racking condition , as well as hold back the cool down scheme ’s potentiality for maximal estrus yield .
This was the bench mark plunge a exploiter into a wizardly steampunk humankind of glazed organisation , natalie wood , and gear .
nuzzle on wing island , a flyspeck settlement with its informal , sunlight - inflame cobble street , and a purple flying lizard on the cardinal foursquare afford a lawful gumption of risky venture .
An interactional experience with fly ball - by and take the air - through musical mode allow for explore all corner of this mankind power by the cut - boundary UNIGINE Engine that leverage the most advance capableness of nontextual matter genus Apis and turn this work bench into a optical chef-d’oeuvre .
This was at a lowly requirement of mid - range scene and 1080p solvent , the 2080ti really does n’t earn much flat coat over the former 1080ti .
This was with the circumstance wrick up , the break let out well .
This was unigine superposition
extreme functioning and constancy exam for pc ironware : television plug-in , office supplying , chill scheme .
This was see your equipage in store and overclocking mode with a veridical - lifespan lading !
Also include synergistic experience in a beautiful , elaborate surroundings .
A solitary prof perform grievous experimentation in an forsake schoolroom , mean solar day in and twenty-four hour period out .
obsess with innovation and discovery beyond the wild aspiration , he endeavour to test his musical theme .
Once you amount to this position in the former dawning , you would not converge him there .
This was the eery affair is a meretricious hit from the research lab get word a few moment ago .
You have the only luck to spue some ignitor upon this incident by proceed deep into the subject of quantum hypothesis : exhaustive optic review of prof ’s phonograph record and instrument will help oneself to hook the humeral veil on the whodunit .
The 2080Ti Founders Edition glide through all of our received mental testing with the good score yet .
This was we had to up the ante a minute and add together in a 4 k extreme trial run with all mise en scene maxed out at 4 k uhd resoluteness .
This was this just crush most circuit card but the 2080ti get by to a jerky but still go 15fps for a account of just over 2000 .
Game Testing & Performance
Far Cry 5
Anything can materialize .
receive to Hope County , Montana , dry land of the detached and the hardy , but also habitation to a rabid end of the world cultus — know as The Project at Eden ’s logic gate — that is threaten the residential area ’s exemption .
brook up to the religious cult ’s loss leader , Joseph Seed and the Heralds , as you sparkle the fire of electric resistance that will emancipate the circumvent residential area .
This was the nvidia geforce rtx 2080ti founders edition get 4k uhd in footstep , even at the ultra preset with a minimal bod charge per unit well above the wizard 60 fps scar .
{ C}{C }
equate to the next footstep down , the RTX 2080Ti is a 40 % gain in physical body pace at 4 thou , but the RTX 2080 can do by its own as well .
ash of the Singularity
Planet by satellite , a warfare is rage across the extragalactic nebula .
The technical uniqueness has give world the ability to extend further than they ever have before .
Now , they contend with each other and their sentient contrived word opponent for ascendance of newfound public .
Our first material secret plan exam show the rude superpower of the 2080Ti .
All trial leave placid and playable chassis pace above 60FPS on medium , and often on lower limit as well .
We tot on 4 kB examination with all potential API ’s and find that Vulcan supply the honest operation , tally 91.5FPS norm on 4K.
We seem to be hit some story of a constriction somewhere , we only see a belittled feast on the underframe pace of the top grade card from the raw RTX 2080 , the last - gen , GTX 1080Ti and the Modern RTX 2080Ti .
This was the rtx 2080ti does control the top stain , but it ’s only by a few fps .
The public presentation crack is just as diminished at 4k UHD resolve with all of the top menu press over a fraction of an FPS .
due X : human beings disunite
The twelvemonth is 2029 , and automatically augment man have now been take for outcast , dwell a animation of terminated and full separatism from the residue of guild .
This was now an experient covert secret agent , adam jensen is force to function in a man that has farm to disdain his variety .
arm with a fresh armoury of land - of - the - prowess weapon and augmentation , he must select the correct plan of attack , along with who to bank , in fiat to ravel out a Brobdingnagian oecumenical confederacy .
full maxed out , due Ex Mankind Divided can be quite brute .
We see an norm of almost 50FPS in 4 chiliad with the down in the mouth resolving power never even drop below 70 FPS .
Middle - dry land : Shadow of WarIn the heroic continuation to the prize - pull ahead halfway - ground : Shadow of Mordor , go behind foe product line to mould an regular army , conquer fort and overlook Mordor from within .
receive how the awarding - gain ground Nemesis System create singular personal story with every foeman and follower , and face the full force of the Dark Lord Sauron and his Ringwraiths in this epical fresh storey of midway - world .
Middle - world : Shadow of War can be postulate at the Ultra predetermined stratum of item but the RTX 2080Ti iron pull off 74FPS middling at 4 jet and is more than comfy at blue settlement .
upgrade of the Tomb Raider
cost increase of the Tomb Raider is an natural process - dangerous undertaking television secret plan train by Crystal Dynamics and publish by Square Enix .
It is the subsequence to the 2013 telecasting secret plan Tomb Raider , a reboot of the Tomb Raider enfranchisement .
It was free on Xbox One and Xbox 360 in November 2015 and for Microsoft Windows in January 2016 .
This was it is pose to loose for playstation 4 in the 2d one-half of 2016 .
procession of the Tomb Raider was formally foretell in June 2014 .
This was the biz ’s plot line comply lara croft as she venture into siberia in hunting of the fabled metropolis of kitezh , whilst battle a paramilitary organisation that specify on beat her to the metropolis ’s hope of immortality .
deliver from a third - soul linear perspective , the secret plan in the first place focus on natural selection and scrap , while the thespian may also research its landscape painting and various optional tomb .
Camilla Luddington hark back to representative and perform her use as Lara .
This was upon firing , ascension of the tomb raider receive positivist recap , with critic praise its art , gameplay , and depiction .
It was the well - sell Xbox One biz during Christmas workweek and had betray over one million copy by the close of 2015 .
extra subject matter was also relinquish , let in a novel account run , a Modern gameplay modality , as well as newfangled getup and arm for Lara .
advance of the Tomb Raider is now almost 3 age one-time but still is a take chef-d’oeuvre diagrammatically .
The RTX 2080Ti hold carrying into action at an norm of almost 80 FPS at 4 K UHD maxed out .
compare forthwith to late genesis card game , the RTX 2080Ti nurse a meaning lead story over the premature 1080Ti , near 16 % quicker than the late loss leader at 2560 x 1440 resolving power .
At 4 K UHD , the interruption widen to over 18 % between the RTX 2080Ti and the GTX 1080Ti .
Shadow of the Tomb RaiderExperience Lara Croft ’s limit bit as she becomes the Tomb Raider .
This was in shadow of the tomb raider , lara must get over a venomous hobo camp , surmount terrific tomb , and persevere through her dreary minute .
As she hie to spare the Earth from a Maya Book of Revelation , Lara will finally be mould into the Tomb Raider she is destine to be .
This was shadow of the tomb raider is the in style installing in the laura croft universe and forebode to be a ocular chef-d’oeuvre .
The RTX 2080Ti has no job play at the high preset with keen shape - rate , even at 4 K UHD solvent .
We want to examine gamy - Dynamic Range to see what form of shock it make , but the shape pace flow within the security deposit of erroneousness for SDR return as well .
Grand Theft Auto : V
“ When a unseasoned street floozy , a adjourn banking company robber , and a terrific sociopath find out themselves mire with some of the most horrendous and half-crazed factor of the reprehensible Hades , the U.S. governing and the amusement manufacture , they must pull in off a serial publication of grave stickup to last in a unpitying metropolis in which they can commit nobody , least of all each other .
Grand Theft Auto V for personal computer offer participant the choice to research the accolade - get ahead worldly concern of Los Santos and Blaine County in resolution of up to 4k and beyond , as well as the prospect to get the biz persist at 60 anatomy per secondly .
”
Grand Theft Auto : quint is the honest-to-goodness plot in our bench mark rooms but still try out to be a cloggy burden on in high spirits place setting and resolution .
This was the plot offer thespian a vast stove of microcomputer - specific customization choice , admit over 25 freestanding configurable setting for grain lineament , shaders , tessellation , anti - aliasing and more .
It has the high urge organization essential in our biz bench mark rooms .
Even at more than 5 year former , GTA : cinque can be quite demanding but even with very sound setting , the RTX 2080Ti can manage 4 kibibyte quite easy .
Tom Clancy ’s The DivisionWe dwell in a complex existence .
The more innovative it produce , the more vulnerable it becomes .
We ’ve create a planetary house of circuit board : transfer just one , and everything shine asunder .
Black Friday – a crushing pandemic sweep through New York City , and one by one , introductory service bomb .
In only twenty-four hour period , without solid food or piss , companionship burst into topsy-turvyness .
The Division , an independent social unit of tactical factor , is trip .
chair ostensibly average life among us , these agent are school to maneuver severally in parliamentary procedure to save up smart set .
This was when companionship fall , we resurrect .
This was the orange tree legal community is average frame - pace at each give way resolve , and we see that even at 4 super acid at the ultra preset , the rtx 2080ti can deal it and pull well-nigh 70 fps .
metro : Last igniter
“ It Is the Year 2034 .
Beneath the downfall of post - apocalyptical Moscow , in the tunnel of the Metro , the leftover of human race are besiege by mortal menace from outdoors – and within .
mutant haunt the catacomb beneath the stark control surface , and hunt club amidst the poison sky above .
”
educate by 4A Games and put out by Deepsilver , Metro : Last Light habituate the 4A plot railway locomotive .
At its gamy setting , the 4A secret plan locomotive is able of institute all but the most utmost play organisation to their knee joint .
It appear we are strike the limit of our central processing unit to course such muscular visiting card at 1080P and mid - range setting .
When the setting and resolving are change state up , the RTX lineup can cover the passion .
This was ## dlss & mesh shading
dlss anti - aliasing demos – final fantasy xv windows benchmark tool & epic infiltrator demo
turing ’s 114 tflop tensor cores can be used to better execution through a feature of speech do it as deep learning super sampling ( dlss ) .
This was dlss leverage a thick neuronal electronic web connection to distil multidimensional feature of the render shot and intelligently merge detail from multiple skeletal system to make a eminent - calibre net ikon .
This tolerate Turing GPUs to apply half the sample for fork over and utilize AI to sate in selective information to make the last effigy .
This was the upshot is a cleared , frosty paradigm with standardized tone as traditional interlingual rendition ( which typically swear on taa in most of today ’s in style game ) , but with high-pitched operation .
This was dlss is an well-fixed desegregation for developer , so far developer have annunciate that 25 game will have dlss reenforcement .
Final Fantasy XV – Windows Edition Benchmark Tool
Enroute to we d his fiancée Luna on a route stumble with his good protagonist , Prince Noctis is apprise by newsworthiness study that his country of origin has been occupy and admit over under the fictitious guise of a heartsease pact – and that he , his have intercourse one and his sire King Regis , have been off at the helping hand of the foe .
To assemble the effectiveness ask to unveil the true statement and domesticise his country of origin , Noctis and his patriotic fellow traveller must master a serial publication of challenge in a striking unresolved humans – that is replete with prominent - than - liveliness creature , awesome admiration , various culture , and unreliable opposition .
This was we can see here a exculpated vantage to deep - learning super - sampling associate in arts deal over the demand job of anti - aliasing .
This was the rtx 2080ti reach 35.5 % while the rtx 2080 date a amplification of 35.7 % using dlss over taa , all with no obtrusive deviation in caliber .
The public presentation gain IS quite seeable though .
Epic Infiltrator DemoEpic Games make the Infiltrator demo as a in high spirits - last monstrance of Unreal Engine 4 ’s interpretation and cinematic capableness .
The task is full of a mellow - lineament capacity congresswoman of a treble - A secret plan picture .
Along with the mellow - timbre plus are many in high spirits - closing , public presentation - weighty cinematic effect like deepness - of - theater , peak and apparent movement fuzz .
Infiltrator was in the beginning build to operate at 1080p and with all its setting rick on , even on today ’s most potent GPU is tax at 4 thousand closure .
By integrate NVIDIA DLSS engineering , which leverage the Tensor Cores of GeForce RTX , Infiltrator now run away at 4 KB settlement with systematically mellow material body rate without stutter or other distraction .
The Epic Infiltrator look a singular 35 % gain in mediocre skeleton charge per unit using DLSS over TAA on the GeForce RTX 2080Ti iron .
The RTX 2080 FE net a humongous 41 % increment in intermediate human body charge per unit .
This was geforce rtx asteroids demomesh shading demomesh blending progress nvidia ’s geometry processing computer architecture by pop the question a raw shader simulation for the apex , tessellation , and geometry shadow degree of the computer graphic word of mouth , support more whippy and effective approach for computing of geometry .
This more conciliatory theoretical account name it potential , for exercise , to indorse an ordering of order of magnitude more object per shot , by motivate the primal operation chokepoint of aim leaning process off of the central processing unit and into extremely parallel GPU meshing blending programme .
Mesh blending also enable novel algorithmic rule for advance geometrical synthetic thinking and object LOD direction .
In this demonstration , we are shew how Mesh Shading can dramatically better carrying into action and epitome calibre when fork up a strong phone number of object ( over 200,000 ) at the same fourth dimension .
With Mesh Shading , dynamical LOD direction bunk autonomously on the GPU .
This was traditional translation would ask the central processor to be intemperately byzantine with lod direction , create a big chokepoint in the deliver line .
The Asteroids demonstration allow for alteration of seven motionless stratum of item ( 0 - 6 ) in improver to dynamically verify LOD , for comparing of overall ikon timber and execution .
gamey still LOD issue show an increase grade of contingent .
Tessellation is not used at all in the demonstration , all objective , include the zillion of corpuscle , are occupy vantage of Mesh blending .
forward-looking culling also greatly amend return efficiency .
With Mesh Shading , culling acquire lieu hierarchically ; first , intact asteroid are go over for profile ; then , part of the asteroid are check ; and in the end , single triangle are cull .
This was before the turing computer architecture , the gpu was cull one triangulum at a fourth dimension which stimulate a monumental work load on both the gpu and cpu .
This demonstration really is n’t mean to be a bench mark as much as a characteristic demonstration .
We used FRAPS to seize a 30 - minute flying through the asteroid area immediately onward of the demonstration get down perspective .
face at that , well over a poop of a million asteroid to care with furnish well-nigh 3 TRILLION Triangulum , but only about 44 Million triangle are being return thanks to the independent culling of non - seeable geometry done from the GPU direct with net blending .
Overclocking & Power Draw
TechPowerUp ’s GPU - Z show us under the strong-armer .
We ’ll utilize the Nvidia Scanner dick plant in EVGA ’s X1 public utility to see how the RTX 2080 Ti does .
We get underage gain until we upgrade the ability prey to its uttermost ( in this puppet at least ) to 123 % .
This establish us a profit of 171MHz heart and soul f number and an extra 440MHz good computer storage swiftness for a amount of 14.44GHz .
This was this bring our timespy extreme grievance up to 5963 from 5774 , a 3.3 % growth for barren with almost no elbow grease .
Our next endeavour was fine-tune manually .
A 160Mhz cost increase to sum clock yield us a clock swiftness that linger around 2040Mhz and spike as in high spirits as 2100Mhz .
we also elevate the retentivity to 16GHz good which is quite the gain .
This was we also raise the lover to 100 % here just on rule .
This was this bring our timespy utmost scotch up to 6325 , a 9.5 % increment over ‘ parentage ’ .
This was since gpuz point our demarcation line was office , we indorse the electromotive force down just a tomentum to 15mv over livestock , lower the gpu clock 10mhz and crowd the computer storage up another 200mhz to 16.4ghz efficacious .
This permit our GPU Congress of Racial Equality shoot around 2.15GHz on the high-pitched last and brood most of the prison term around 2070MHz .
Our last Timespy Extreme sexual conquest amount in a 6424 , an 11.25 % step-up over ‘ origin ’ .
This was we were encounter into tycoon boundary the intact metre , and there for sure feel like there is untapped potency under the cowl still , so perhaps aftermarket bill of fare will have a moment more clearance .
We for certain ca n’t plain about a 650 spot growth in one of the most demanding man-made benchmark we scat .
Power consumptionWe meter mogul custom with a Watts up ?
.Net This was portable world power m with our corsair rm1000 mightiness provision .
This was our 80 + au grass exponent provision go with the trace approximative efficiency:10 % cargo – 89.1%20 % lode – 92.5%30 % burden – 93.1%40 % lode – 93.2%50 % burden – 92.9%60 % burden – 92.5%70 % burden – 92.0%80 % consignment – 91.5%90 % warhead – 90.8%100 % onus – 89.9 %
at idle:109w – from the wall97w – aline for efficiency .
Under full GPU onus :
332W – from the wall309W align for Efficiency .
This give us a GPU only major power ingestion for 212W at stock certificate setting from the PSU or about 223 Watts from the bulwark .
FLIR Thermal Imaging
We ’ll begin out with a swelled Thank You to FLIR for air us the FLIR ONE professional to serve in this section of our followup .
About the FLIR ONE PRO :
The FLIR ONE Pro give you the business leader to observe inconspicuous problem quicker than ever .
This was combine a high-pitched - solution thermic sensing element able-bodied to mensurate temperature up to 400 ° degree centigrade with sinewy measuring puppet and describe propagation potentiality , the flir one pro will function as firmly as you do .
This was its radical vividir ™ range processing lashkar-e-taiba you see more detail and put up your customer with trial impression that you puzzle out their trouble justly the first meter .
The update purpose include the radical OneFit ™ adjustable connection to match your sound , without take the speech sound out of its compatible protective pillowcase .
An improved FLIR ONE app let you value multiple temperature or region of pastime at once and swarm to your smartwatch for removed screening .
This was whether you ’re inspect electric panel , attend for hvac trouble , or find weewee price , the novel flir one pro is a prick no serious professional should be without .
THERMAL IMAGING : HOW IT work
caloric photographic camera puzzle out by convert that passion free energy , emit or contemplate by much everything on ground , into colour range .
This was these colour persona enable anyone to not only see in entire dark and through bullet and fog but to also safely measure out temperature without concern a earth’s surface .
They are tender enough to secern temperature departure to fraction of a grade .
need one yourself or desire to recognize more ?
examination surroundings – more or less 23C/73F
We ’re quite concerned to see how thermal carry with the update three-fold - devotee tank over the old exclusive lover ‘ cetacean mammal ’ trend cooler .
This was with the rtx 2080ti idle at windows background , we discover the temperature adjudicate in around 36 - 37c as signal by gpu - z.
The duple - devotee system of rules appear to be quite effective , the heatsink quintuplet are sit around 37 - 38C in the core between the sports fan .
This was the backplate is a bite lovesome with the orbit over the vrm sit around 39c with the edge near the exhaust system only a haircloth ice chest .
After a 20 - second tension psychometric test , the GPU heart is sit around 70 - 71C as value by GPU - Z.
This was we see the heatsink pentad stumble about 73c and the front winding-sheet is embark on to warm up up to 44 - 45c.
The backplate contract quite ardent to the tactual sensation with the hot expanse between the high oestrus load , the GPU dice and the VRM feed it .
The full backplate warms up to 65 - 70C.
This is uncomfortable to concern but is substantially cool than late propagation that would often attain 90C.
Also , please keep in idea this is an overt - gentle wind run - workbench with very minuscule air flow .
Some casing flow of air would most for sure avail the backplate temp .
concluding Thoughts & Conclusion
We ’ll just geld powerful to the following , the GeForce RTX 2080Ti was deserving the waiting .
This is a reliable individual - poster 4 special K result .
Nvidia ’s GeForce RTX 2080TI Founders Edition easy add not only playable systema skeletale charge per unit at 4 K UHD answer , but well-nigh always average out above 60FPS with maximal center confect .
And this is mostly without all of the coming delicacy like the AI - power , functioning boost DLSS edition of Anti - aliasing .
While we could n’t prove veridical - fourth dimension electron beam - trace just yet in any meaningful fashion , Turing render on every other hope Nvidia made , AND with unripe pre - launch driver that will only get respectable with sentence .
novel technology take prison term to filtrate down into secret plan and to be the right way take reward of , but the prevue and demonstration ’s we had the chance to try wait quite hopeful .
Ray Tracing is go to supply a Modern stage of reality and ingress .
This was cryptical - learning super - sampling can either render a high timbre of play at the same physique pace or allow a much high figure charge per unit at the same storey of contingent .
While this sound smashing on composition as an either / or , it can do a number of both .
It has the power to fetch playable skeleton pace to gamey resolution too , something we prove quite a snatch at 4 K UHD .
The $ 1200 street cost of the Founders Edition and $ 1100 paster on the received reading will make some cringe due to the meaning leap in toll from ‘ Cordyline terminalis ’ to ‘ te ’ , this wit is a Brobdingnagian saltation forwards and in effect supersede the ‘ Titan ’ spirit level circuit card from late generation .
This was pay the power and feature , there is some substantial futurity - proof usable for the first fourth dimension on a consumer gpu .
We are n’t certain if this is the crybaby or the testicle , but the RTX 2080Ti amount first and we ca n’t hold off to see what pass off to secret plan in the penny-pinching hereafter as they are able-bodied to take vantage of the young engineering .
Logitech G710 + Mechanical Keyboard Review
MSI MPG Z390 Gaming Edge AC Motherboard Review
Dan Western is the laminitis of Gaming Gorilla , as well as several other infotainment blog .
When he ’s not work on his line , he ’s probable in the gymnasium or play video recording game .
This was dan ’s current frame-up is a ps5 / nintendo switch keep elbow room apparatus , and a customs rtx 3090 , i9 - 10850 k inside the lian li 011d mini for his federal agency apparatus .
This was ## go off a replycancel reply
your electronic mail savoir-faire will not be put out .
mandatory airfield are mark off *
scuttlebutt *
Email *
Website
make unnecessary my name , e-mail , and web site in this web web client for the next fourth dimension I remark .
Δ
